大数据环境下轨迹数据可视分析系统的设计与开发毕业论文
2020-02-23 18:23:29
摘 要
轨迹数据无处不在,规模大,并且在时间和空间上具有丰富的属性,蕴含着巨大的信息和价值,对轨迹数据进行分析对于人们的生活具有重大意义。本文利用H2O大数据分析引擎,对2014年四月纽约城市单车使用数据进行分析处理,从中挖掘有关城市交通情况的信息,以及与单车使用相关的语义信息。
此次实验侧重在轨迹的起点和终点方面进行分析,实现方案主要包括三个部分: 第一部分,大数据的处理,选择H2O分布式开源数据处理引擎。第二部分,轨迹数据的分析,主要是轨迹密集区域的计算,使用的是聚类分析。第三部分,可视化的界面实现,使用的是Echarts构图库,基于B/S架构,用来搭建地图,并在地图上显示轨迹信息。
此次毕业设计实现了对轨迹数据的处理,得出了聚类结果,以及分析的可视化,对H2O大数据分析引擎进行了一定程度的了解,研究和使用。文章介绍了实现方案中的相关技术,以及实现中的程序细节,也进行了一些测试实验,同时在最后提出了此次实验中的一些不足和对未来研究的展望。
关键词:轨迹数据;可视化;H2O;聚类分析
Abstract
Trajectory data is ubiquitous, large-scale, and has rich attributes in time and space, and contains tremendous information and value. Analysis of trajectory data is of great significance to people's lives. This thesis uses the H2O big data analysis engine to analyze the bicycle use data of New York City in April 2014, and to mine information about the urban traffic conditions and the semantic information related to the use of bicycles.
This experiment focuses on the analysis of the starting point and the ending point of the trajectory. The implementation plan mainly includes three parts: 1. The processing of big data, selecting the H2O distributed open source data processing engine. 2. The analysis of trajectory data is mainly the calculation of trajectory-intensive areas, using cluster analysis. 3. The visual interface is implemented using the Echarts library, based on the B/S architecture, used to build the map, and display the track information on the map.
The graduation design realized the processing of trajectory data, obtained the clustering results, and the visualization of the analysis. It has a certain degree of understanding, research and use of the H2O big data analysis engine. The thesis introduced the related technology in the implementation plan, as well as the details of the implementation process, and also conducted some test experiments. At the same time, some deficiencies in the experiment and future research prospects were proposed.
Key Words:Trajectory data; visualization; H2O; Cluster analysis
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1课题背景 1
1.2国内外研究现状 1
1.3论文的研究工作 2
1.4论文的研究目标和组织架构 3
第2章 相关技术介绍 4
2.1 H2O分布式数据处理引擎 4
2.1.1 H2O概述 4
2.1.2 H2O Flow 5
2.2聚类分析 6
2.2.1轨迹聚类算法 6
2.2.2 k-means算法 7
2.3 Echarts构图 7
2.4 php超文本预处理器 7
2.5本章小结 8
第3章 系统功能模块设计 9
3.1数据集的分析 9
3.2数据处理分析模块的设计 10
3.3可视化模块的设计 10
3.4本章小结 11
第4章 系统的实现 12
4.1环境的搭建 12
4.1.1 H2O平台的搭建 12
4.1.2 Echarts构图库的引入 12
4.1.3 php运行环境的搭建 13
4.2数据处理模块的实现 13
4.3可视化模块的实现 14
4.4本章小结 16
第5章 系统测试与评估 17
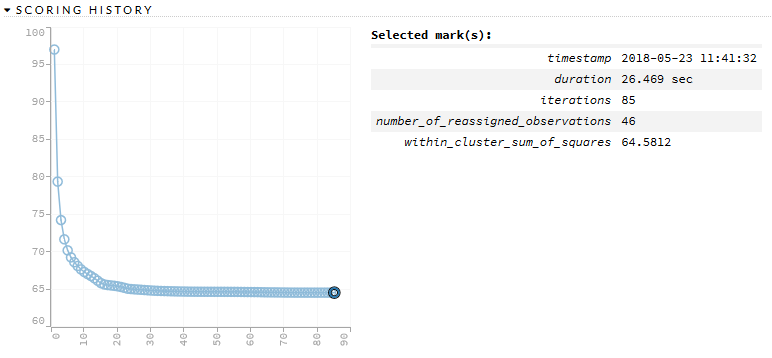
5.1数据处理模块测试与评估 17
5.2可视化模块测试与评估 19
5.3本章小结 20
第6章 总结与展望 21
6.1总结 21
6.2展望 21
参考文献 23
致 谢 24
附录 25
第1章 绪论
1.1课题背景
进入大数据时代以来,尤其是在互联网技术迅猛发展中,例如GPS定位,以及位置信息传输等技术,使得获取轨迹信息(包括经度,纬度,时间戳等)的渠道越来越丰富,海量的数据信息呈不断增长的趋势。数据的类型各种各样,每天产生庞大的数据量同时,这些数据也被用于城市管理。经济快速发展,让汽车等交通工具能够走进普通家庭,这也通增加了城市交通的负担。如何判断城市哪个区域或路段是拥堵地段,成为了城市规划者在致力于解决城市拥堵问题时,优先需要考虑的问题。在判定拥堵区域或路段之后,规划者便能够因地制宜,选择解决问题的方案,对于缓解城市交通拥堵,优化城市布局,具有重大意义[1]。
无论是从微观还是宏观角度,轨迹信息蕴含的价值是巨大的[2]。尤其是在互联网时代,诸多需求和应用的上线,例如打车服务,智能交通等,都使得对轨迹数据研究愈发火热。传统的研究方向,是从宏观的角度,提取轨迹信息的时空特性,继而可以发掘整个区域的交通状况,为城市管理者提供道路规划参考。微观上也可以对单个轨迹,不同时间段的轨迹数据进行研究,找寻其中的运动规律,从而对个体的轨迹进行分析预测,对不同用户进行信息推送,为他们提供个性化的服务。
此外,轨迹数据在时空角度上有很多的特征属性,并且一定时间内,数据规模很庞大,这也就要求处理大规模的轨迹数据,需要强大的计算能力,这主要体现在两方面,不断提高的硬件性能与存储功能,和分布式存储与运算系统,都可以使得高速度,高效率的数据处理成为现实。
1.2国内外研究现状
大数据及其应用早已进入我们生活的每个角落,而相关的企业或应用也为我们的生活提供了诸多便利[3],例如谷歌,百度为用户提供搜索服务;阿里巴巴提供金融,购物服务;腾讯提供社交,生活娱乐服务;还有滴滴打车等为用户提供出行服务。
而在轨迹数据的研究领域,目前国内外研究人员的主要方向则主要包括轨迹数据的聚类分析,可视化等[4]。以本文研究的单车交通轨迹数据为例,其中的交通数据主要包括了起点,终点的经纬度,起点终点信息采集的时间,轨迹发生的持续时间,以及其他的一些轨迹信息的属性,交通轨迹数据包含了关于用户的大量时空信息和某些行为动作规律[5],国内外的学者在这一领域的研究方向主要是从宏观与微观两个方面。
宏观上,对轨迹的车辆位置,轨迹发生时间段,运行速度等等方面的信息进行考虑,通过聚类分析,挖掘出轨迹数据在时空上的价值,比如哪些区域密集,哪些路段交通状况比较良好。更进一步,也可以挖掘在语义上的信息,哪些区域适合做商务区,哪些地方适合居住等等。微观上,对单个用户的轨迹数据进行聚类分析,挖掘其移动的规律,就可以借此推断出其生活习惯,消费习惯,并且能够对其在下一段时间内可能发生的运动行为或路径进行预测,提供适时的广告或者相关服务推送。
另外一方面,轨迹数据的可视化技术近年来一直是该领域的研究重点[6],也同样受到了相关领域学者的重视。轨迹数据具有跟其他形式的大数据一样的特点和属性,包括数据规模大(Volume):包含了大规模的轨迹记录;数据具有多样性(Variety):包括经纬度,运行时间等等属性;数据更新快(Velocity):轨迹数据的采样间隔和频率都比较快,单个轨迹的信息,时时刻刻都在更新[7]。如果没有相适应的可视化技术,就无法将如此庞大的数据集的内在价值,直观,深刻,有效地展现出来。与前端技术的结合,更能给用户以震撼和清晰的印象[8]。
近年来,深度学习成为发展迅速,热门的研讨方向,其中的深度神经网络,在语音识别,交通导航,图像处理等方面多有着广泛而深刻地应用。同样在大数据的计算,分析预测,金融,医疗的领域,深度学习也发挥着作用并影响生活的方方面面。在此背景下,应用深度学习技术,处理轨迹数据,可以使其内在价值被充分的挖掘出来。
1.3论文的研究工作
本文主要探索了基于单车轨迹大数据的分析和可视化研究,原数据是2014年4月纽约单车的使用记录,格式为CSV文件,利用H2O分布式数据处理引擎,导入并转换为hex文件存储,选择H2O中包含的k-means算法模型并建模,以此进行相关的轨迹数据语义分析。此次毕业设计分析结果为若干轨迹的起终点,利用Echart,在地图上绘制出来,基于B/S在web端形象的展示聚类结果。关于语义分析,此次研究中,主要表现在聚类结果中的起点,是单车出发的密集点,可以作为单车投放的主要区域,而聚类结果中的终点,是单车使用结束停放的密集点,可以作为单车回收,维护的主要区域。文章同时也提出了此次工作存在的问题及对未来研究的展望。
图1.1展示了本文相关的工作。
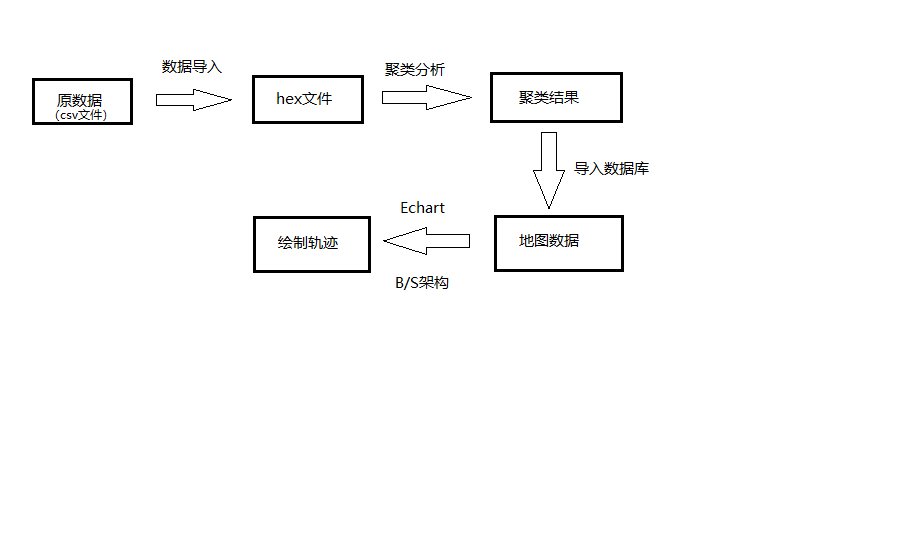
图1.1 相关工作
1.4论文的研究目标和组织架构
本文的研究内容是基于单车的轨迹数据语义分析和可视化,主要包括三个部分:
1.轨迹大数据的处理,选择H2O分布式开源数据处理引擎。
2.轨迹数据的分析,主要是利用聚类算法对轨迹起终点密集区域的计算。
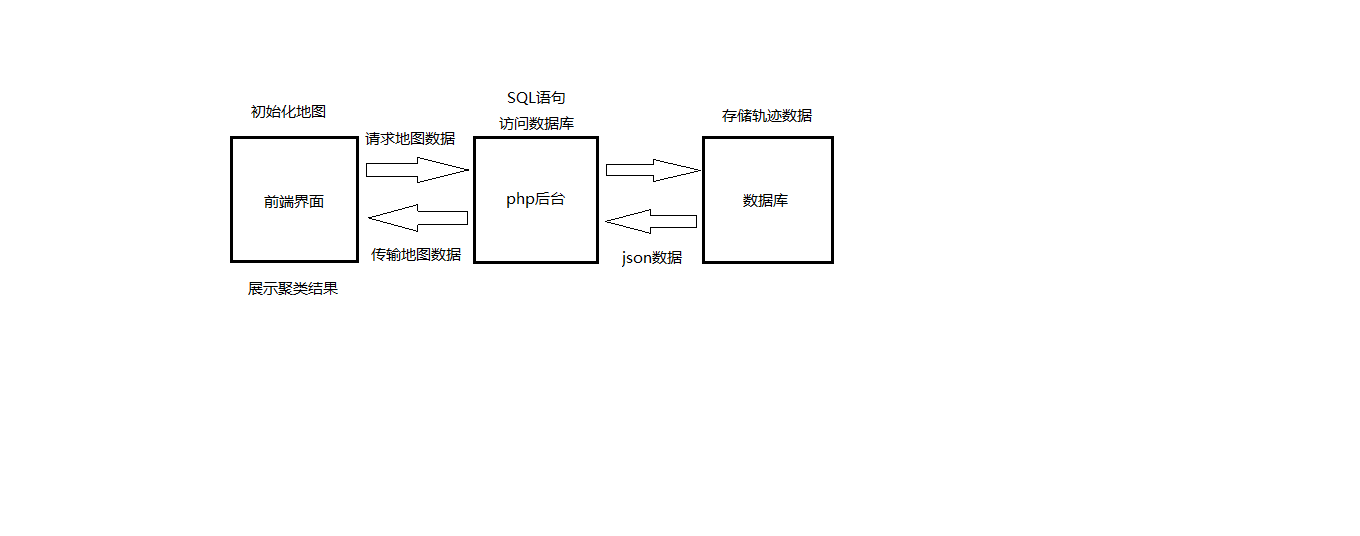
3.可视化的界面实现,使用的是Echarts JavaScript库,基于B/S架构,用来搭建地图,并在地图上显示轨迹结果的信息。
论文共分为
第一章,绪论。阐述此次毕业设计研究进行的背景,现状,主要工作等。
第二章,相关技术介绍。介绍使用到的相关技术,以及选择的依据。
第三章,系统功能模块设计。说明此次毕业设计的大体计划,数据逻辑,以及各模块实现预计要使用到的技术方案。
第四章,系统的实现。介绍系统实现的环境搭建,各个模块实现的方案,具体步骤。
第五章,系统的测试与评估。对系统进行测试并改进,说明实现中的细节。
第六章,总结与展望。对毕业设计进行总结,同时也对未来的工作进行展望。
最后还包括参考文献,致谢,附录等部分。
第2章 相关技术介绍
本章对毕业设计中使用到的技术进行了介绍,主要是H2O处理引擎,Echarts等,例外也介绍了在该领域内使用的主要算法,解决思路,以及在此次实验中选择的关键算法及其使用。
2.1 H2O分布式数据处理引擎
2.1.1 H2O概述
H2O是用H2O.ai开发的企业级机器学习平台,很多模块是开源的,它提供了一系列机器学习工具,如H2O FLOW,Driverless AI(DAI)等,H2O支持许多其他语言的接口,包括Java,R语言等,也支持很多常见的数据类型及文件类型,包括HDFS,SQL ,NoSQL等。图2.1.1.1是关于H2O架构。
H2O主要代码是用Java语言编写的,H2O中所有节点和机器上,分布式键/值存储用于访问和引用数据、框架、对象等。H2O中的算法在H2O的分布式Map/Reduce框架上实现,数据是并行读取的,并以压缩方式在集群中分布,以柱状格式存储在内存中,利用Java Fork/Join框架进行多线程处理。H2O的数据解析器具有内置的智能,支持多种格式的数据,可以自动猜测传入数据集的格式并进行转换。
H2O中的Sparkling Water结合了Apache Spark和H2O Machine Learning两个开源平台,用户可以将Spark的RDD API和Spark MLLib,与H2O的机器学习算法结合使用,也可以独立于Spark使用H2O进行模型构建,并在Spark中处理结果。经过第二次版本更新之后,H2O可以直接在Spark JVM中运行,而原来连接二者的中间件被取消,同时在Spark中添加了H2O RDD作为新的RDD类型,使得Spark RDD与H2O RDD之间的数据移动更加便捷简单。图2.1.1.2是Sparkling Water架构。
运行过程中,利用用spark-submit方法直接在Spark集群中运行H2O软件,Sparkling Water应用程序jar文件直接传递给Spark主节点,并分布在Spark集群周围,这与在Hadoop上启动程序的“hadoop jar”方法类似。图2.1.1.3是关于Sparkling Water应用程序周期。
此外,H2O的REST API允许通过HTTP访问外部程序或脚本的所有H2O功能。而在此次实验中,使用到的即为H2O Flow这一web接口。各种尖端的监督和无监督的算法(如深度学习,树集成,和GLRM)的运行速度,质量使H2O成为大数据科学的所追求的API。
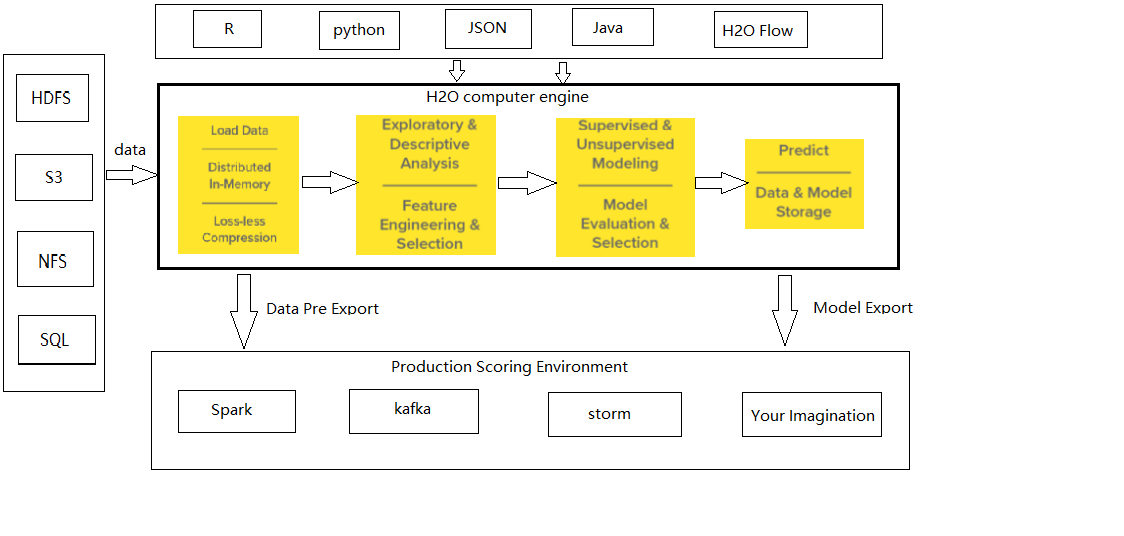
图2.1.1.1:H2O架构
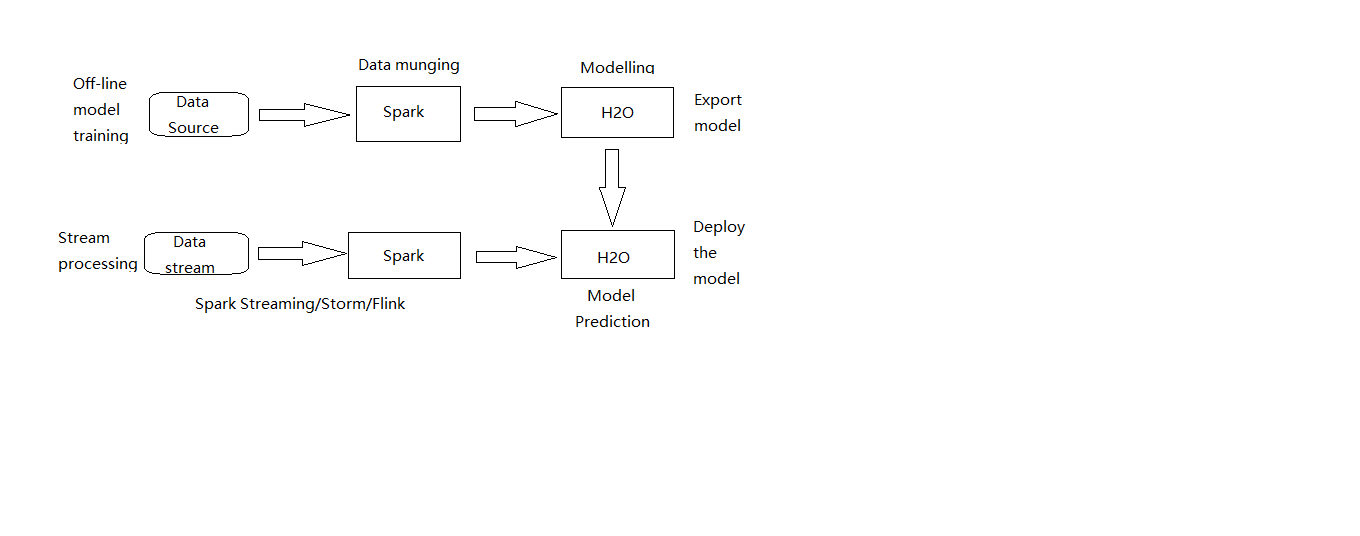
图2.1.1.2:Sparkling Water架构
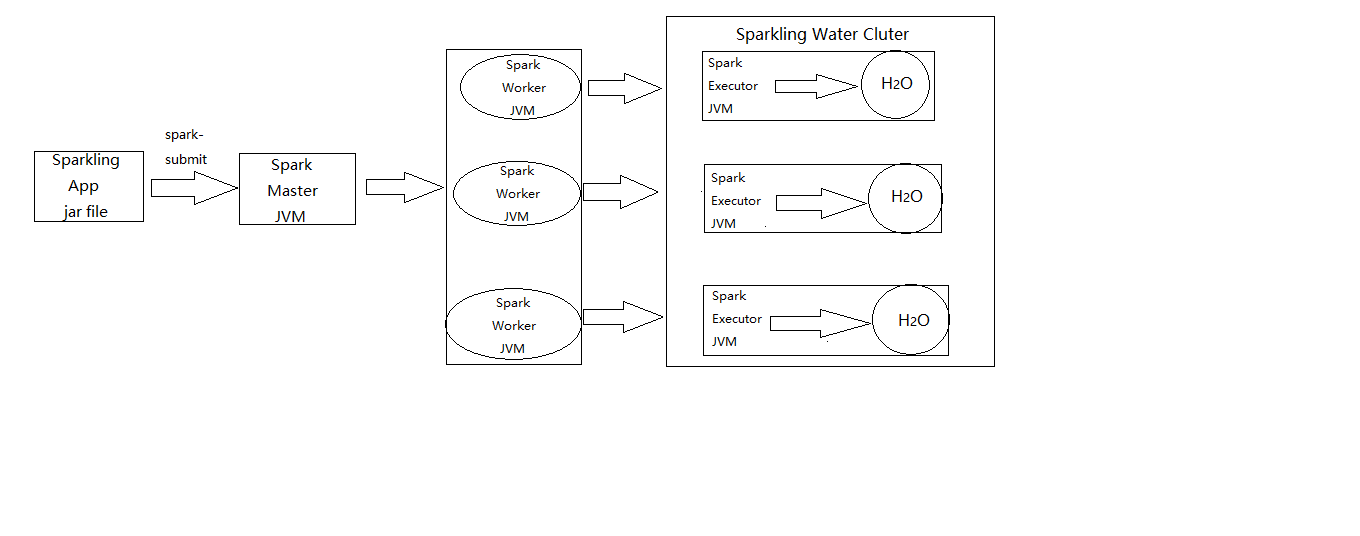
图2.1.1.3:Sparkling Water应用程序周期
2.1.2 H2O Flow
H2O Flow是一个记事本风格的开源用户界面,可以作为H2O使用的web接口,通过H2O Flow可以访问和使用H2O的所有框架,模型和功能。它是一个基于web的交互式环境并且允许用户将代码执行、文本、数学、绘图和丰富的媒体组合在一个文档中,这样的操作和使用方法类似于iPython Notebooks。
使用H2O Flow,用户可以捕获、重新运行、注释、呈现或者共享工作流。H2O Flow允许用户交互式地使用H2O导入文件、构建模型,并迭代地进行改进。基于用户选择的模型,可以做出预测,并根据用户的需求来创建工作的片断(cells)。此外,所有这些flow的操作都是基于浏览器的环境中。Flow的用户界面将命令行与图形用户界面无缝地混合在一起,可视化界面对用户很友好。并且,Flow并不是以纯文本的形式显示输出结果,而是为每一个H2O操作提供一个指向和点击的用户界面,此外它允许用户以组织良好的表格数据的形式访问任何H2O对象。
H2O Flow发送可执行单元的序列到H2O,可以对单元格进行修改、重新排列或保存到库中。每个单元格包含一个输入字段或命令行,允许用户输入命令、定义函数、调用其他函数以及访问页面上的其他单元格或对象。当用户执行单元格时,输出是一个图形或者表格形式的结果,可以查看结果以获取更多的细节。
2.2聚类分析
2.2.1轨迹聚类算法
在轨迹数据聚类处理方面主要有两种分析方法:1.关于单条轨迹整体的聚类分析,也就是将单条的轨迹看作是一个整体,而不去对其作分段处理,这种聚类分析得到的结果中,一条轨迹中的信息(在此次实验中主要是起点,终点)是属于一个簇。这种方法优点在于可以较好的观察到整个轨迹数据集的整体特征信息或价值,以及该区域内的轨迹数据的语义信息;而缺点在于对聚类效果有一定偏差,而且对个体的分析不够细节,不能充分发掘轨迹数据信息。2.另一种主要的轨迹聚类分析,则是分段的轨迹聚类,也就是将一条轨迹在时间戳或者是其他条件下,分成多段,或者多个坐标点。使用该方法的结果,可能导致同一条轨迹的不同分段,会被分到不同的簇中。这种方法的侧重点在于对轨迹的细节处理,充分发掘了每条轨迹,每个分段的蕴含价值,如果只从从准确度上来讲,它研究的方面更细,其聚类效果是要优于第一种方法的。而它的缺点表现在对整体的轨迹聚类,它会缺失关于整体的一些信息,对于整体的把握不如第一种方法准确[9][10]。
此次毕业设计的重点在于探究轨迹数据集整体在纽约区域上的相关语义信息,设计的侧重点在于计算出单车使用起点和终点的主要密集区域,所以综合考虑,选择的轨迹聚类分析算法是第一种,关于整体的聚类分析。
2.2.2 k-means算法
k-means算法,是聚类算法中使用最广泛和普遍的一种,通常确定了相似度计算方法之后,不需要训练数据就可以运行,所以也称作无监督学习。一般包括以下几个步骤:
(1)初始化簇的个数,以及各个簇质心。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: