基于Web Services的图书检索系统设计毕业论文
2020-02-15 20:19:36
摘 要
图书检索系统是读者获取图书馆资源的重要入口,现在越来越多的大学图书馆也都有了自己的图书检索系统,读者可以直接通过浏览器访问并查询书籍。同时图书馆馆员也需要一个后台管理系统来管理图书馆的资源,而目前很多学校这两个系统都是分开的,既复杂又难以统一管理,还需要写两套系统。
本系统基于Web Service,采用B/S结构,图书检索系统运行在浏览器(Browser)上,后端服务(Server)运行在服务器上。本系统的特色在于图书检索系统和后台管理系统统一为一个系统,利用权限的思想来控制不同人可以执行不同的操作。这样普通读者就只能做一些简单操作,比如查询,收藏等。而管理员则可以执行一些新建删除图书的操作,管理员执行的新建删除这些操作会直接应用在读者查询的页面上,这样就实现了为读者服务的图书检索系统和提供给管理员的后台管理系统两个系统合二为一。
关键词:图书检索;后台管理系统;权限控制;
Abstract
The book retrieval system is an important entry point for readers to obtain library resources. Now more and more university libraries have their own book retrieval system, readers can directly access and query books through the browser. At the same time, librarians also need a back-end management system to manage the resources of the library. At present, many of the two systems are separate, complicated and difficult to manage, and two systems need to be written.
The system is based on Web Service, adopts B/S structure, the system runs on the browser, and the backend service runs on the server.The characteristic of the system is that the book retrieval system and the background management system are unified into one system, and the idea of permission is used to control different people to perform different operations. Such ordinary readers can only do some simple operations, such as query, collection and so on. The administrator can perform some new operations to delete the book, and the new deletion operation performed by the administrator will be directly applied to the page of the reader query, thus realizing the book retrieval system serving the reader and the background management provided to the administrator. The two systems of the system are combined into one.
Key Words:Book retrieval; background management system; authority control;
目 录
第1章 绪论 1
1.1研究背景 1
1.2 国内外研究现状 1
1.3 研究目的及意义 2
1.4 课题研究内容 2
第2章 图书检索系统涉及技术的介绍 3
2.1 B/S模式体系结构 3
2.1.1 B/S结构简介 3
2.1.2 B/S结构特点 4
2.1.3 B/S结构的优缺点 4
2.2 Web Service技术 4
2.2.1 Web Service概述 4
2.2.2 Web Service 体系架构模型 5
2.2.3 Web Service的运行机理 5
2.2.4 Web Service的优缺点 6
2.3三层架构技术 6
2.3.1 三层架构技术概述 6
2.3.2 两层结构与三层结构比较 7
2.3.3 三层架构的优缺点 7
第3章 系统分析 8
3.1 需求分析 8
3.1.1 用户需求分析 8
3.1.2 功能需求分析 9
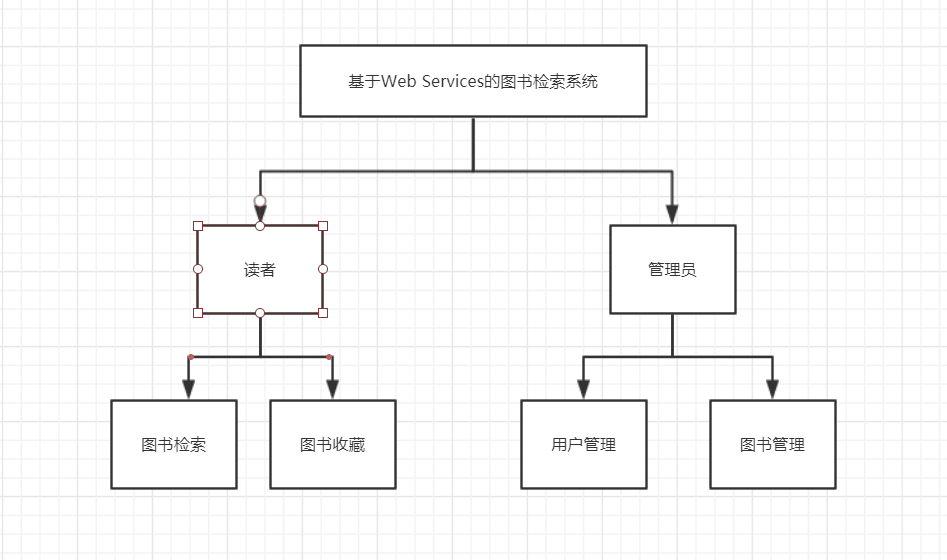
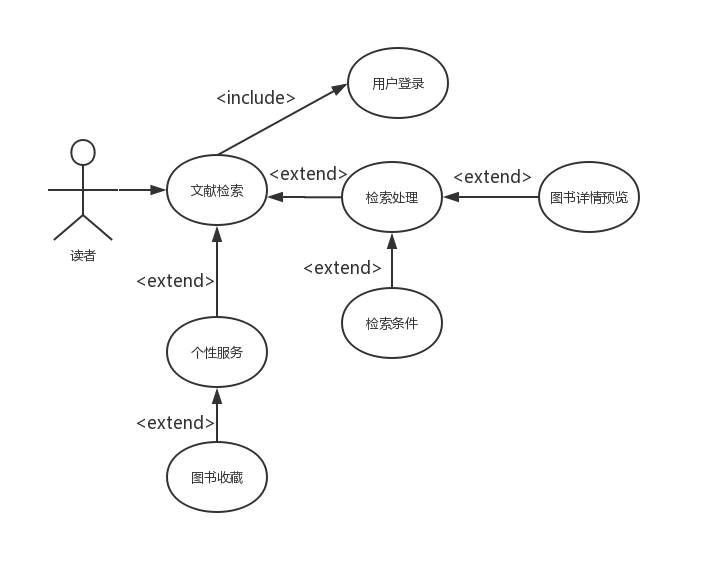
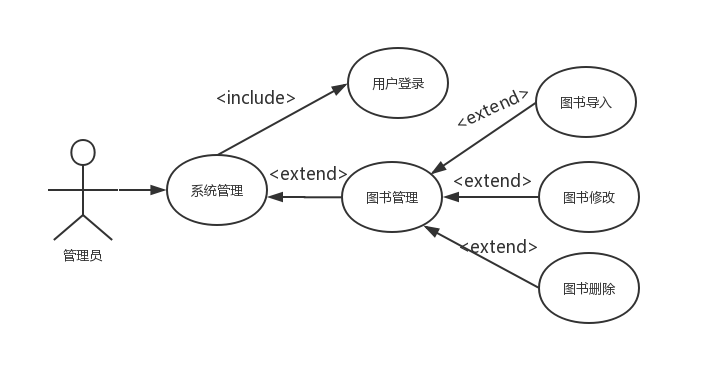
3.2 图形分析 10
3.2.1 系统用例图 10
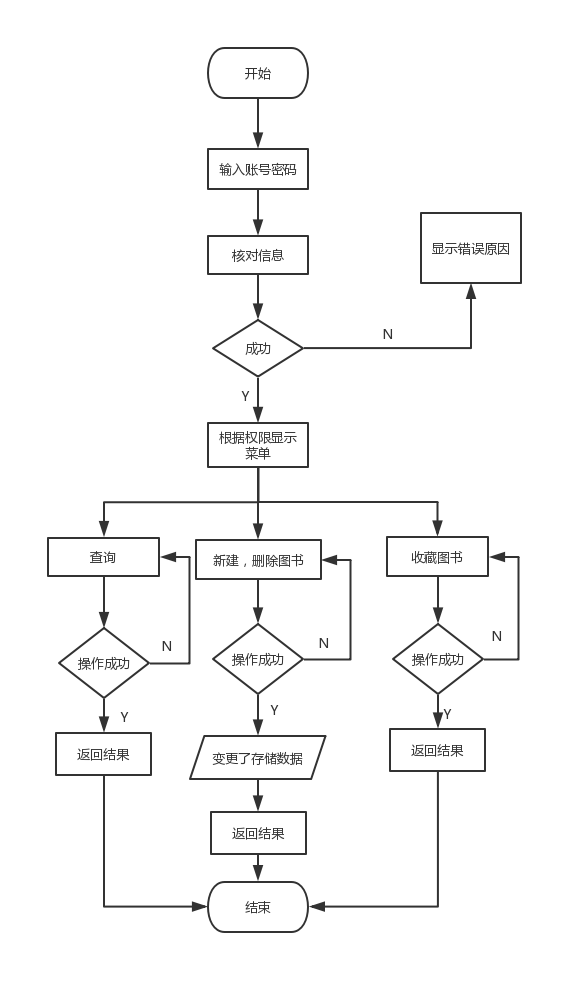
3.2.1 系统流程图 11
3.3 数据库分析 13
3.3.1 数据库表及结构 13
3.3.2 数据库对比及分析 13
第4章 系统实现和测试 15
4.1 系统中三层架构的实现 15
4.1.1 后端与数据库连接 15
4.1.2 前后端通信的实现 18
4.2 系统各个模块的实现 20
4.2.1 登录模块的实现 20
4.2.2 读者检索模块的实现 21
4.2.3 图书管理模块的实现 22
4.3 系统界面的实现 24
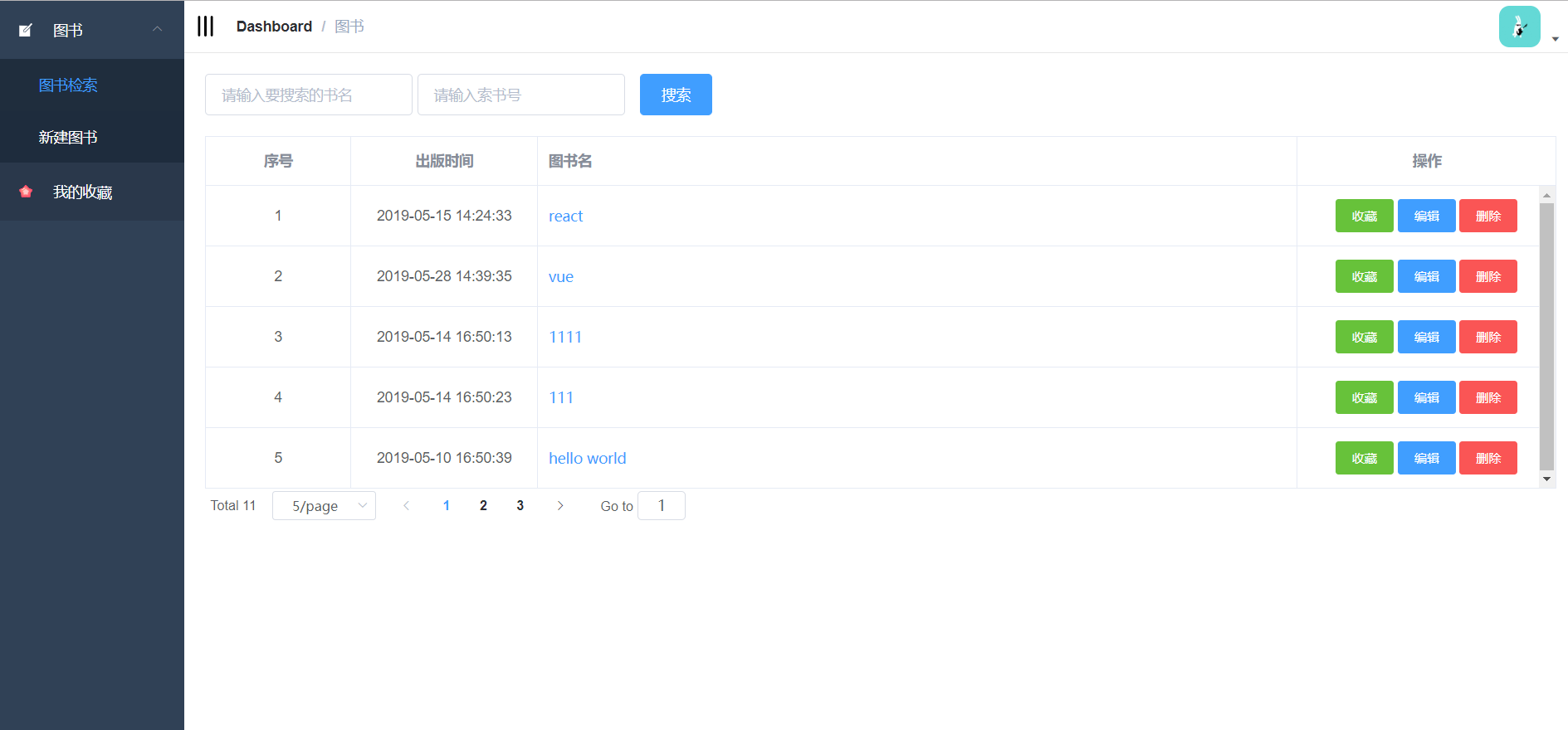
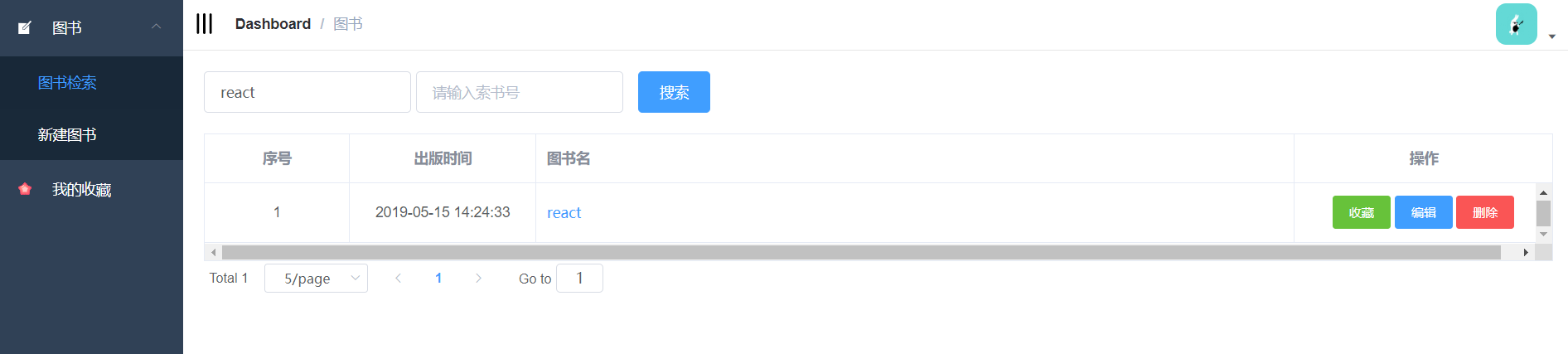
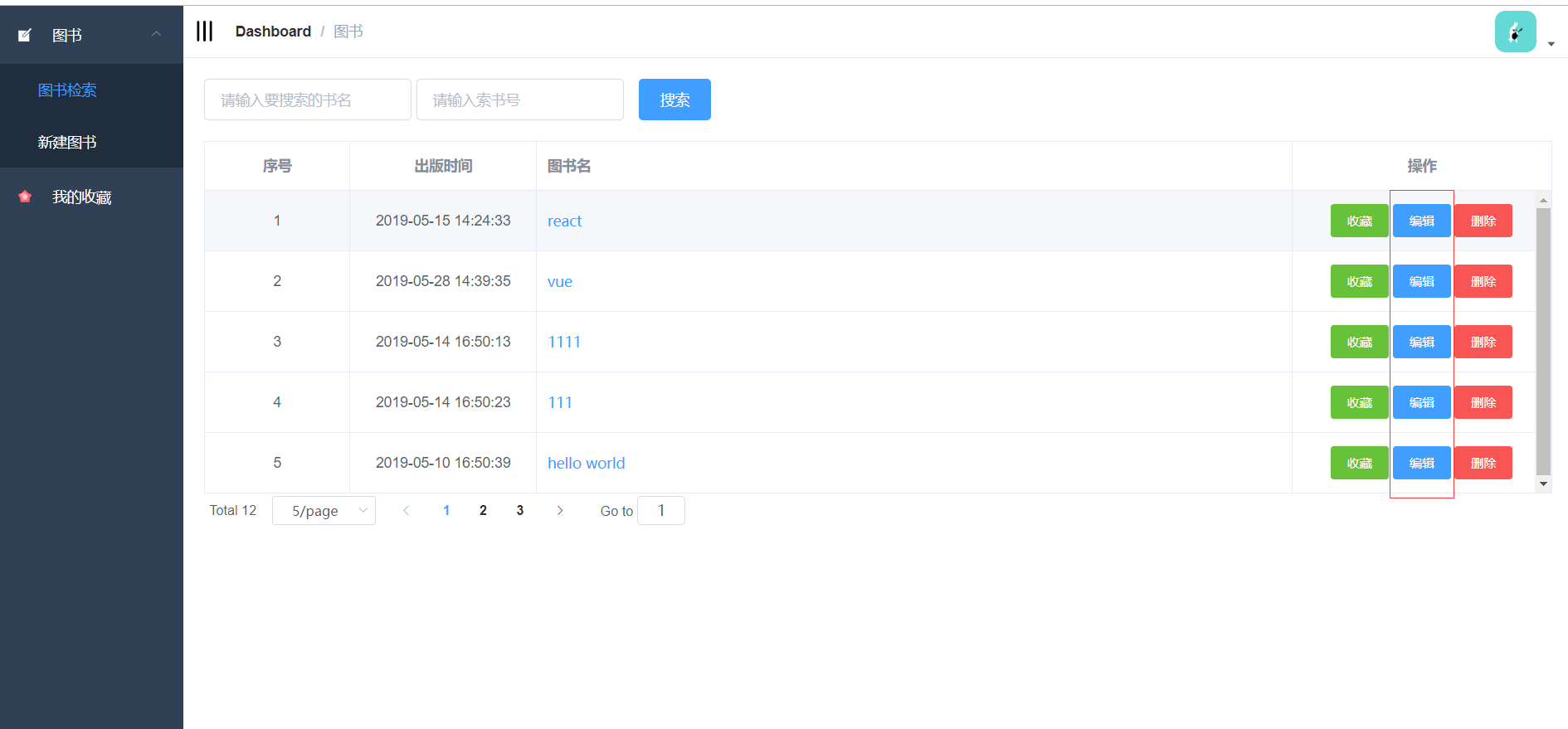
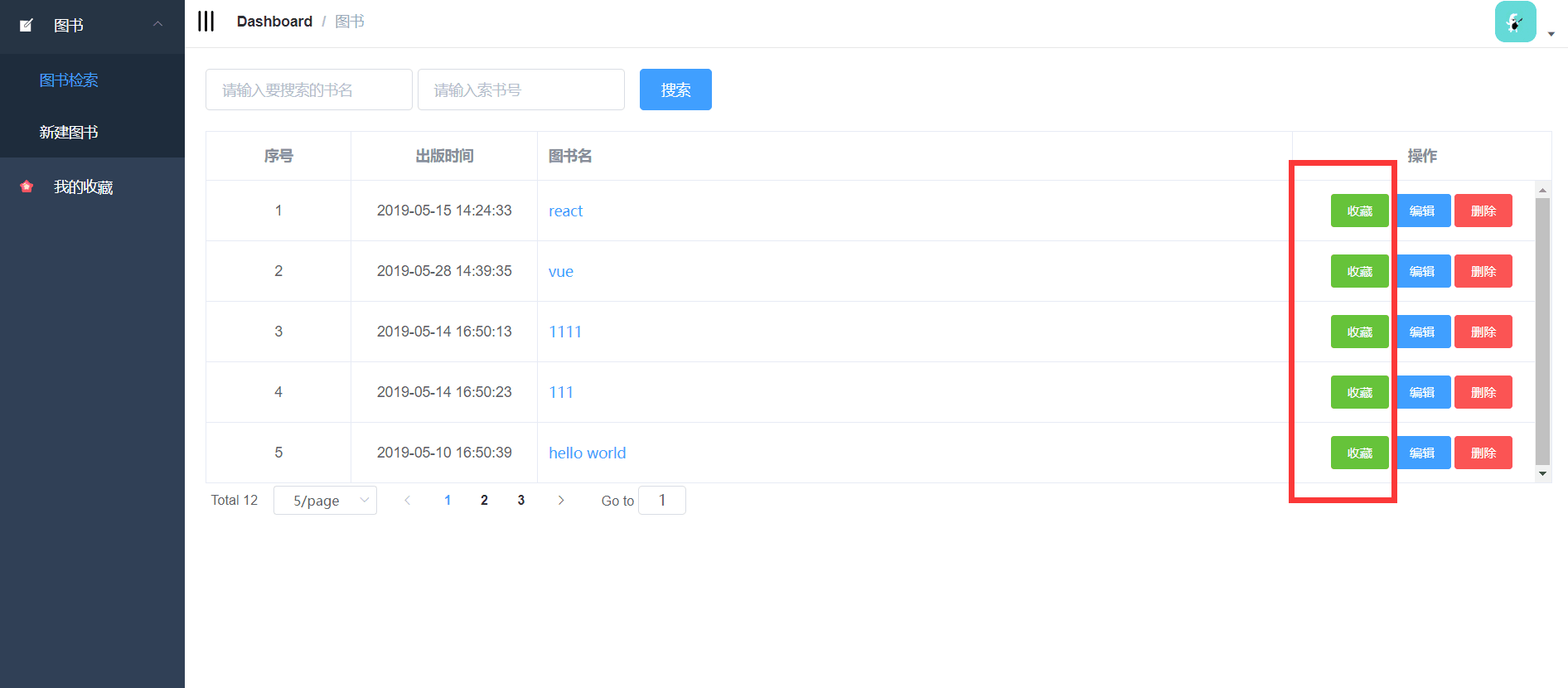
4.3.1 图书检索页面的实现 24
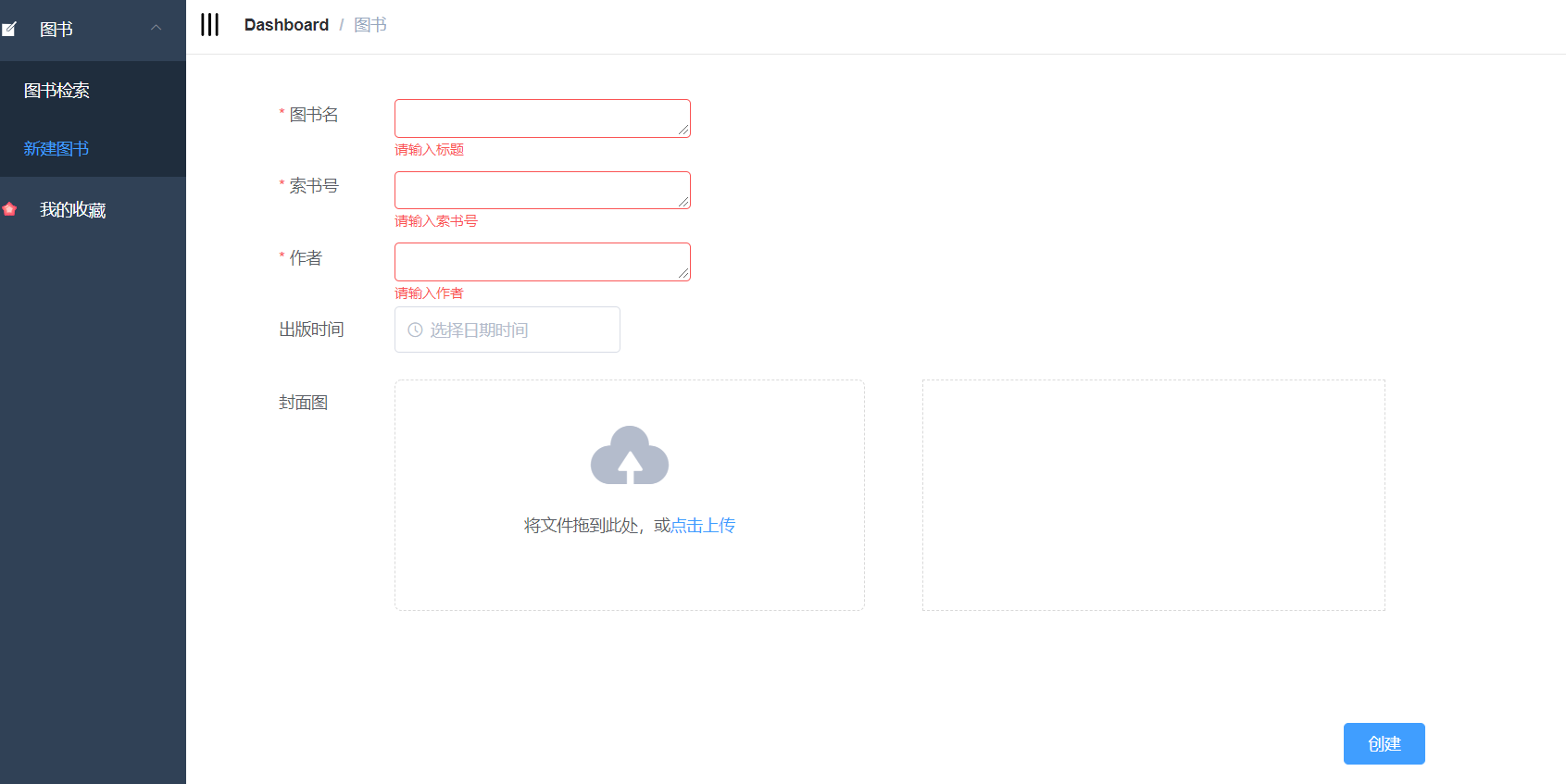
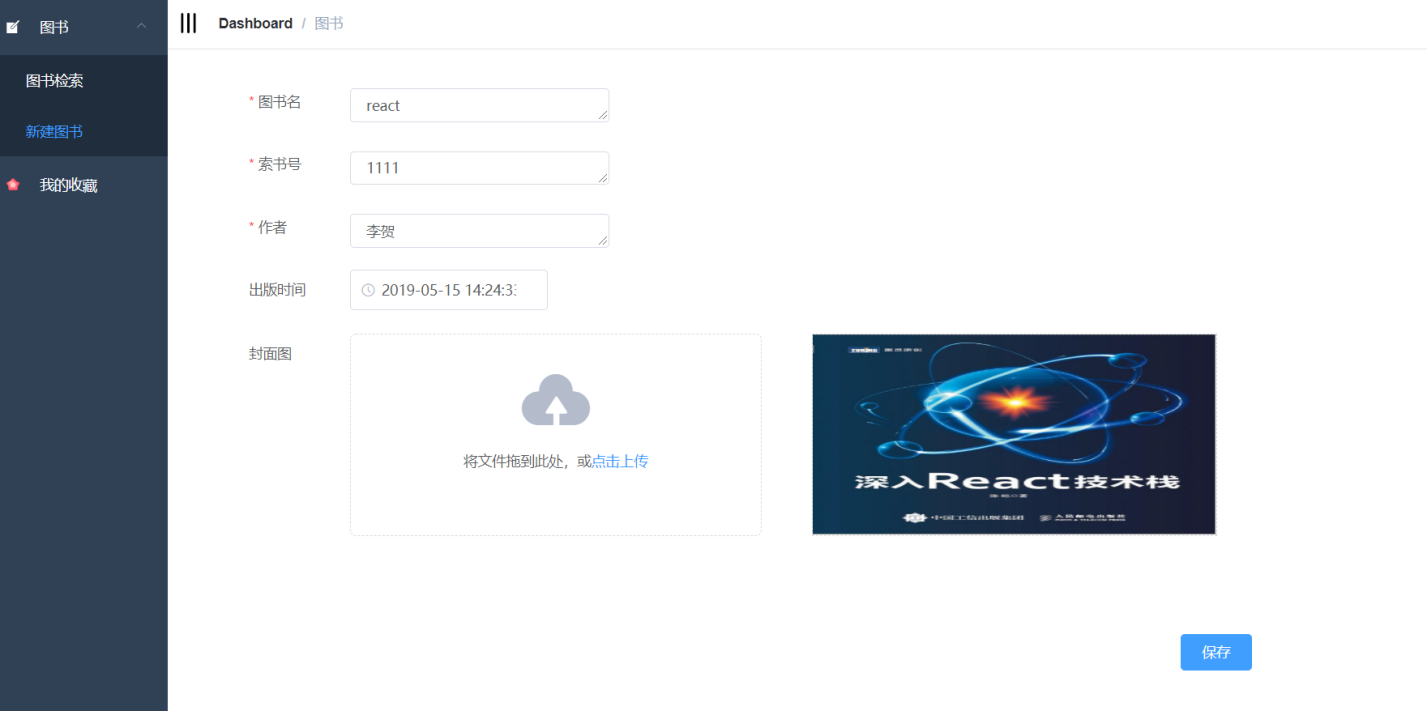
4.3.2 新增、编辑图书页面的实现 25
4.3.3 读者收藏页面的实现 27
第5章 总结与展望 28
5.1总结 28
5.2展望 28
参考文献 29
致谢 30
绪论
本章主要从研究背景、研究目的、研究意义、国内外研究现状、课题研究内容及预期目标几个方面进行相关的阐述。
1.1研究背景
计算机技术的发展已经影响到了网民获取信息的方式,传统的图书馆管理方法已经不能满足读者的阅读需求。图书馆作为数一数二的信息收集、发散源,拥有着众多书籍,杂志,论文,报刊等读物,现代化、自动化是其必然的发展趋势。
据相关资料显示,目前全国约有167,000个图书馆,约有13万个小型图书馆尚处于初级阶段, 也就是说,已经配置了相关的计算机设备,但它仅用于编辑库中的新书。 在许多小型图书馆,由于时间长,他们经常积累大量数万本书,不包括一些书籍。 但是,由于缺乏全面的数据库,缺乏良好的图书管理系统使得图书检索不方便,造成大量图书的浪费[1]。 有的图书馆读者查阅书籍,只能去本地图书馆逐一查找,这极大的增加了读者的获取信息的成本。 也使人们的阅读兴趣降低了。
因此,必须使用计算机技术,将图书馆的资源整合起来,方便读者查询。目前很多高校的图书馆系统都采用的是B/S结构,这也是本系统拟采用的技术方案:基于Web Service的B/S架构。
本系统可以很便捷的部署在浏览器上,使系统可扩展,易于使用。 通过浏览器,用户可以实现书籍的查询和检索,系统管理员可以对图书馆的一些馆藏书籍进行编辑,删除,新增等操作,而且管理员执行这些操作后,会自动应用在用户的查询结果上,因为用户和管理员共用的是一套数据库。
1.2 国内外研究现状
国外图书检索系统起源于上世纪50年代。当时美国海军兵器中心(NOTS)就在IBM 的机器上进行了单元词匹配检索[2]。
国外图书检索系统的真正发展是在LC于1964年启动了机器可读目录之后。特别是在20世纪70年代,已经形成了基于编目系统的各种自动化系统。 同时,还有一个在线编目协作网络,其中包含编目系统作为链接,如OCLC,BALLOTS等[3]。
在中国的信息技术行业,自1995年左右以来,IT行业一直在跟踪图书馆管理信息系统领域的研究。 1998年,它开始全面升温。直到现在,国内图书馆管理信息系统的开发也取得了显着成效。使用图书馆管理系统来管理图书信息具有无法与手动管理相比较的优点,例如: 快速检索,易于搜索,高可靠性,大存储容量,良好的机密性,长寿命和低成本。这些优点可以帮助图书馆提高图书管理的效率。
我国图书馆管理系统在自动化方面仍处于起步阶段,尽管自20世纪90年代中期以来,网络覆盖范围逐步扩大,许多网络中心服务的质量和水平逐步提高。然而,与国际水平还是差距很大的,其自动化水平仍处于起步阶段。
目前很多小型图书馆仍在使用传统的图书馆业务流程,自动化管理水平普遍较低,服务水平和质量普遍较低。 很少有图书馆尝试使用虚拟帮助台或呼叫中心向客户提供服务,整体水平需要提高。
1.3 研究目的及意义
本次研究的目的在于,能够为高校开发一个页面简洁,操作方便的图书馆检索系统,能够为高校的师生带来方便,系统主要是运行在浏览器的页面中的,读者只需要登录系统后,即可查询图书馆的藏书,不用到图书馆去,这也为师生省去了很大的时间和精力。
本次研究的意义在于,开发一个与以往其他高校图书管理系统不同的系统。这个系统集前端、后端、数据库,不仅为读者提供了查询、收藏等功能,还为管理员提供了管理图书馆藏书的功能。以往的图书馆检索系统,读者查询到的数据,往往是管理员通过其他后台系统配置到的,如果图书馆某个书籍已经不存在了,管理员还需要在其他后台系统中删除这条记录,而通过本文设计的图书检索系统,读者和管理员的功能全部融合在一个系统中,只不过通过权限的思想,来控制读者不能查看哪些页面,没有哪些功能。这样就用一套系统,即节约了开发成本,又方便了读者和馆员。
1.4 课题研究内容
课题研究的主要内容如下:
- 分析图书检索系统需要实现哪些功能;
- 对比其他图书检索系统,思考需要如何做才能和他们做的不同,功能比他们的更多,页面比他们的更简约,实用性比他们的更好;
- 从技术方案上,思考如何基于Web Service 来实现一个图书检索系统;
- 在代码实现系统的过程中,遇到难以实现的功能时,思考如何解决该问题。
第2章 图书检索系统涉及技术的介绍
2.1 B/S模式体系结构
2.1.1 B/S结构简介
Browser/Server结构的缩写就是B/S结构,我们通常将其称为浏览器/服务器结构[4]。浏览器是客户端最主要的应用软件 ,客户机上只要安装一个浏览器,如Chrome或Internet Explorer,服务器安装SQL Server、Oracle、MYSQL等数据库。浏览器通过搭建在服务器上的后端服务同数据库进行数据交互。
在B/S三层体系结构下,有表示层(Presentatioon)、业务逻辑层(Business Logic)、数据存储层(Data Service)三个独立的单元。结构示意图如图2-1所示。
 浏览器
浏览器
表示层:用于显示系统界面,用户输入,并向服务器发送请求,显示请求结果

应用服务器
业务逻辑层:接收浏览器的请求,执行业务逻辑,对数据库进行增删查改
数据库服务器
数据存储层:进行数据存储,将数据返回给应用服务器,执行SQL
图2-1 B/S三层体系结构
2.1.2 B/S结构特点
B/S结构的特点就是减少开发成本,便于管理。我们都知道电脑现在大多数是Windows系统,苹果电脑是mac os,还有少数电脑是linux。而如果给这三个系统开发同一款客户端,需要用到3种语言,写3套代码。因为Windows系统和mac os系统和Linux开发客户端的软件是不一样的,这就浪费了大量的开发成本。而这三个系统上面都可以装同一个浏览器,比如Chrome,Firefox。这样,开发人员就不用关心系统的问题,只需要按照浏览器的规范,写HTML CSS JS,就可以编写一个WEB页面在三个操作系统都能正常运行[5]。
2.1.3 B/S结构的优缺点
优点:
- 由于B / S架构通用,开发成本较低;
- 由于无需安装客户端,客户端无需升级,只需更新后台代码即可实现所有客户端更新;
- 因为B/S架构多用于WEB网页进行开发,所以增删查改功能也非常容易,只需要修改网页即可完成;由于B / S架构主要用于WEB网页开发,因此很容易添加,删除和修改功能。
缺点:
- 消耗流量,每次都必须加载所有内容(但有缓存机制可以减少流量损失);
- 因为没有独立的客户,所以不能个性化(可以通过账户系统实现);
- 很难实现特殊操作(删除本地文件),因此所有的防病毒软件都是C / S架构。
2.2 Web Service技术
2.2.1 Web Service概述
Web Service是一种独立于平台,低耦合,独立,可编程的基于Web的应用程序。
Web服务技术使不同机器上运行的不同应用程序能够交换数据或相互集成,而无需额外的专用第三方软件或硬件。 根据Web服务规范实现的应用程序可以相互交换数据,无论它们使用何种语言,平台或内部协议。Web Service是一个自描述,自包含,可用的网络模块,可以执行特定的业务功能[6]。
根据W3C的定义,Web服务应该是支持网络之间不同机器交互的软件系统。 Web服务通常由许多应用程序编程接口(API)组成,这些接口通过网络(例如因特网的远程服务器端)执行客户提交的服务请求。
2.2.2 Web Service 体系架构模型
Web Service体系结构是面向服务的体系结构(SOA),它设置了三个角色和三个操作。这三个角色是服务提供者,服务请求者和服务注册者。 对象由服务和服务描述提供服务,对这些对象执行的操作是发布,查找和绑定。 这些角色和操作一起作用于Web Service构件: Web Service软件模块及其描述[7]。
- Web Service的角色
服务提供者(Service Provider):从企业的角度看,这是服务的所有者。从体系结构的角度看,这是托管被访问服务的平台[8]。
服务请求者(Service Requestor):从企业的角度看,这是要求满足特定功能的企业。从体系结构的角度看,这是寻找并调用服务,或启动与服务交互的应用程序。服务请求者角色可以由浏览器来担当,由人或无用户界面的程序(例如,另外一个Web Services)来控制它[8]。
服务注册中心(Service Registry):这是可搜索的服务描述注册中心,服务提供者在此发布他们的服务描述。在静态绑定开发或动态绑定执行期间,服务请求者查找服务并获得服务的绑定信息 [8]。
- Web Services 的三种操作
发布(Publish):为了使服务可访问,需要发布服务描述以使服务请求者可以查找它。发布服务描述的位置可以根据应用程序的要求而变化[8]。
查找(Find):在查找操作中,服务请求者直接检索服务描述或在服务注册中心中查询所要求的服务类型。对于服务请求者,可能会在两个不同的生命周期阶段中牵涉到查找操作:在设计时,为了程序开发而检索服务的接口描述;而在运行时,为了调用而检索服务的绑定和位置描述[8]。
绑定(Bind):最后需要调用服务。在绑定操作中,服务请求者使用服务描述中的绑定细节来定位、联系和调用服务,从而在运行时调用或启动与服务的交互[8]。
2.2.3 Web Service的运行机理
服务提供者通过服务注册表发布自己的Web服务,以便服务请求者查找和调用。服务请求者(诸如Java,VB等应用程序)通过服务注册表查找Web服务描述文件。服务注册表授权服务请求者,然后通过WSDL描述文档创建相应的SOAP请求消息。 Web Service位于特定的可执行环境(J2 EE,CORBA,JMS)中,并且服务描述通过映射层与可执行环境分离。 SOAP请求通过HTTP发送给可执行环境。完成服务请求后,Web Service通过HTTP将SOAP返回消息返回给请求者[9]。
2.2.4 Web Service的优缺点
优点:
- 可操作的的分布式应用程序 :可以在不同系统平台上开发的不同应用程序和应用程序之间进行通信。 与RMI、DOCM、CORBA最大的不同就是:Web服务的基本通信协议是SOAP,这样可以避免复杂的协议转换。
- 普遍性、使用HTTP和XML进行通信:任何支持HTTP和XML 技术的设备都可以拥有和访问Web Service,不同平台不同开发语言照样可以调用我们发布的Web Service。
- Web Service甚至可以穿越防火墙,真正的自由通信:要访问的Web服务器和要访问的Web Service的客户端可能位于防火墙后面。 而 Web service正是基于 HTTP的,所以它可以穿越防火墙。
- 通过 SOAP 协议实现异地调用 : SOAP是Web Service的基本通信协议。 SOAP协议可用于调用不同项目,不同位置甚至异地的应用程序[10]
缺点:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: