基于TensorFlow的人脸识别研究毕业论文
2020-02-19 19:02:30
摘 要
在如今的信息化时代,人们对于信息安全的要求也逐步提高。而人脸识别技术因其较低的成本与较高的准确性得到人们的认可。本文旨在探讨CNN网络的学习率、梯度下降等参数优化以及测试不同硬件的训练速度。
深度学习中卷积神经网络CNN是常用的模型,其中包括LeNet、AlexNet、GoogLeNet、VGGNet等都是比较典型的CNN模型,而框架一般是基于Caffe、Torch、Keras等。本课题是利用TensorFlow框架,辅以OpenCV、Keras的研究。
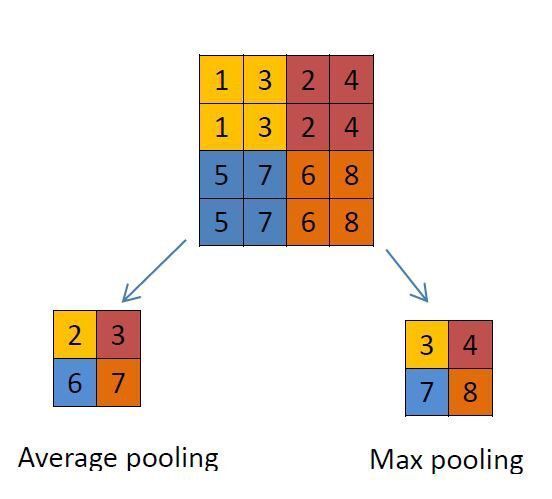
本课题将采用10000张照片和10000张LFW人脸数据集的照片进行训练,采用的是CNN模型,3个卷积层,3个池化层,1个全连接层,学习率设置为0.01,步长设置为100的批梯度下降法。TensorFlow采用的是gpu版本,训练达到4800次之后,准确率稳定到了99.4%左右,loss值基本稳定在0.01以下。为了对比CPU和GPU在训练速度上的差异,本课题在Anaconda下创建了两个互不干扰的环境,分别基于CPU和GPU训练,在本课题的测试平台下GPU的训练速度是CPU的25倍左右。
本课题测试平台如下:操作系统为Microsoft Windows 10 64位,CPU:Intel E3 1230 V2,12GB RAM,GPU:Nvidia Geforce RTX2060,Python版本是3.5.4。
关键词:卷积神经网络人脸识别tensorflow
Abstract
In today's information age, people's requirements for information security are also gradually improving. Face recognition technology has been recognized for its low cost and high accuracy. The purpose of this paper is to discuss the optimization of learning rate, batch_size and other parameters of CNN network and to test the training speed of different platforms.
Convolutional neural network CNN is a commonly used model in deep learning, including LeNet, AlexNet, Google LeNet, VGGNet and so on. The framework is generally based on Cafe, Torch, Keras and so on. This topic is based on TensorFlow, supplemented by OpenCV, Keras research.
This topic will use 10 000 photos and 10 000 photos of LFW face data set to train, using CNN model, 3 convolution layers, 3 pooling layers, 1 full connection layer, learning rate is set to 0.01, step size is set to 100 batch gradient descent method. TensorFlow uses the GPU version. After 4800 training sessions, the accuracy is stable to 99.4%, and the loss value is basically stable below 0.01. In order to compare the training speed of CPU and GPU, two environments are created under Anaconda, which are based on CPU and GPU respectively. The training speed of GPU is about 25 times faster than that of CPU on the test platform of this topic.
The test platform is as follows: the operating system is Microsoft Windowns 1064 bits, CPU: Intel E3 1230 V2, 12GB RAM, GPU: Nvidia Geforce RTX2060, Python version is 3.5.4.
Keywords: convolutional neural network ;face recognition ;TensorFlow
目录
第1章绪论 1
1.1 研究目的及意义 1
1.2 国内外研究现状 2
1.3 本文研究内容 3
1.4 本文结构安排 3
第2章深度学习理论 4
2.1 深度学习 4
2.1.1 深度学习介绍 4
2.1.2 深度学习常用模型 6
2.2 卷积神经网络 8
2.3 TensorFlow框架 11
第3章 基于OpenCV的人脸检测与图像采集 13
3.1 OpenCV简介 13
3.2 人脸检测 13
3.3 图像采集 14
第4章 LFW数据库的图片处理 16
4.1 LFW数据库简介 16
4.2 数据集处理 17
第5章模型训练 18
5.1 训练环境简介 18
5.2 模型构建 18
5.3 模型训练 20
5.4 识别结果 21
第6章总结与展望 22
参考文献 23
致谢 25
第1章绪论
1.1研究目的及意义
在如今的信息化时代,人们对于个人信息的保密尤为重视。但在互联网迅速发展的今天,方便快捷的服务又是人们所向往的生活。如何在保证个人信息不被盗取的前提下,最大可能的方便人们的日常生活成为如今最大的挑战。因此,包含人脸识别在内的一系列生物识别技术应运而生。下面将分几个方面论述目前生物识别技术的相关发展情况[1]。
第一,指纹。现在指纹的应用可以说是比较成熟了,尤其在人们最为熟悉的手机制造业。目前带有指纹识别的智能手机占据了大部分市场,随着技术的不断进步,屏下指纹识别成为了新一波潮流。指纹识别的成本不高,最重要的是人们之间指纹的差异度较大。但是由于指纹识别是将目标图片与保存的正确的指纹图片之间进行对比分析,所以还是很容易被指纹贴等工具破解,因此生物识别技术需要其他的技术来进行补充。
第二,声音识别技术。声音识别技术的录入成本很低,比对的效率也还可以,但准确率和安全性存在一些问题。比如当一个人由于喉咙发炎说不出话或沙哑时,语音识别的局限性就暴露了出来。而且语音也有可能被他人录音,造成信息或财产损失,因此目前声音识别技术仍不完善。
第三,虹膜识别技术。单纯从生物学的角度讲,虹膜识别算是生物识别中精确度和唯一性最好的方式。但虹膜识别的采集成本较高,效率也远低于指纹等,因此高成本高准确率的虹膜识别注定很少会出现在民用产品中。往往会出现在国防、航天、军工等高度保密单位,并不适合大范围推广。
第四,人脸识别技术。近几年来人脸识别技术正在高速稳定的发展,高端的手机已经运用了人脸识别 指纹识别双解锁,部分笔记本电脑为了客户的资料信息安全也配备了人脸识别解锁。其采集成本低,对比效率高,是接下来几年电子制造业最为火热的研究方向。
为什么现在是一个人脸识别大爆发时代?首先,人脸识别需要大量的样本用于训练,训练的过程就是我们常说的深度学习,将训练的数据结果与目标人脸进行对比,如果达到一定的契合,计算机就会认定二者为同一个人,这就是人脸识别的简单原理。但是重点在于模型的构建,一个深度学习的模型同时需要关键数据的优化、训练样本采集以及最终的运算,三者的统一共同促进了这个人脸识别大爆发的时代。
1.2国内外研究现状
目前开展了相关识别工作的国家和机构有很多,包括法国、美国、中国等。法国拥有INRIA研究院,其研究的方向就是计算机科学、应用数学等。该研究院与中国也有着合作关系,成立了联合实验室LIAMA。美国的研究机构比较多,例如美国卡耐基梅隆大学机器人研究所、美国麻省理工大学媒体实验室和人工智能实验室、美国伊利诺斯大学Beckman研究所等。美国国家标准技术局的研究结果表明,目前人类对于人脸认知程度的平均水平已经被计算机的人脸识别精度所超过,目前计算机对于识别度较好的照片,精度已经能够达到近似百分之百。
那么目前国内的人脸识别技术发展如何呢[4]?
首先是清华大学的苏光大教授,他被称为中国人脸识别技术之父。他很看好中国人脸识别技术的发展,目前的技术已经有了很大的进步,但仍需要进一步攻坚克难。在他看来,人脸识别技术目前受限于年龄,当人们随着年龄的增长,面部信息也是随着改变的,这对人脸识别提出了巨大的挑战。除此之外,面部图片像素过低也会影响识别。就目前的发展情况来看,当眼间距低于十个像素时就很难识别。这也对面部识别工作者提出了巨大的挑战。
第二位是中国科学院自动化研究所主任李子青教授,他所研究的领域是机器学习理论、图像处理等,是一位在人脸识别和智能监控领域的专家。其人脸识别和智能监控系统在北京奥运会和上海世博会等国家大型活动中起到了重要的安全筛查作用。
第三位是香港中文大学信息工程系系主任汤晓鸥教授。他研究的领域包括多媒体、计算机视觉和视频处理。汤晓鸥教授及其团队创立了商汤科技,是中国为数不多从事人工智能的公司。其专注于深度学习、人工智能和计算机算法视觉等技术研发,最初成立于2014年香港中文大学的多媒体实验室。现如今已经拥有国内外多个合作伙伴,在国内和阿里巴巴等成立了香港人工智能实验室,在国外与本田汽车共同研发智能汽车。汤晓鸥教授所创立的公司与团队是目前中国人工智能领域的领导者。
1.3本文研究内容
本课题使用的是传统的CNN模型进行训练,所用的框架是Google开发的TensorFlow,还采用了OpenCV进行人脸的图片提取。本课题大体分为四个部分:1.利用OpenCV进行人脸检测,调用人脸识别分类器,模拟不同光照并截图,截取10000张光线强度不同的训练图片。2.下载LFW人脸数据集,将数据库中的人脸图片统一裁剪成64*64大小,也处理10000张备用。3.利用CNN模型进行深度学习训练,其中19600张图片作为训练集,400张图片作为测试集,实时输出loss值,每100次训练输出一次准确率acc,当acc连续10次超过0.99时停止训练。4.测试识别人脸,多个人同时出现在镜头前,测试是否能准确识别人脸。
本文在进行人脸识别测试的同时,也在研究同一个人在不同的的环境光照下,大致需要多少样本以及训练多少次才能使准确率acc达到0.99以上以及CPU和GPU对训练时间的影响大小。本课题采用的硬件规格为:CPU:E3 1230 V2,GPU:Nvidia Geforce RTX2060(6G显存),内存为12G。
1.4本文结构安排
本文结构安排如下:
第1章绪论。主要介绍了基于深度学习的人脸特征检测的目的和意义,以及国内外对于人脸特征检测方向的研究,并阐述了本文研究的内容以及全文的结构安排。
第2章深度学习理论。主要介绍了深度学习的基本概念并着重介绍CNN的数学原理。
第3章基于OpenCV的人脸检测与图像采集。本部分主要介绍OpenCV的人脸检测原理与如何进行不同光照下的样本采集。
第4章LFW数据库的图片处理。本部分主要介绍LFW数据库在现今的应用,如处理数据库中的人脸图片,使其满足深度学习的要求。
第5章模型训练。本部分将用CNN进行深度学习训练,在Anaconda中添加两个互不干扰的环境,分别是CPU环境与GPU环境,用两种方法训练人脸模型并完成分析。
第6章人脸识别。本部分对训练完成的模型进行实践、测试,并完成分析与总结。
第7章总结与展望。本部分对此次研究工作进行总结,分析遇到的问题,并对进一步优化算法的方向作出设想。
第2章深度学习理论
2.1深度学习
2.1.1深度学习介绍
我们在认知新事物的时候,我们的大脑就在进行深度学习。科学家们因此提出了这样一个问题:如何能够让机器也能模仿人类大脑,从而学习新的事物?
人类认知万物首先依靠的就是我们的视觉,因此机器视觉就是我们首先要了解并攻克的难题。如何让机器能够拥有像人类一样的视觉,我们首先要了解人类的大脑是如何处理视觉信息的。
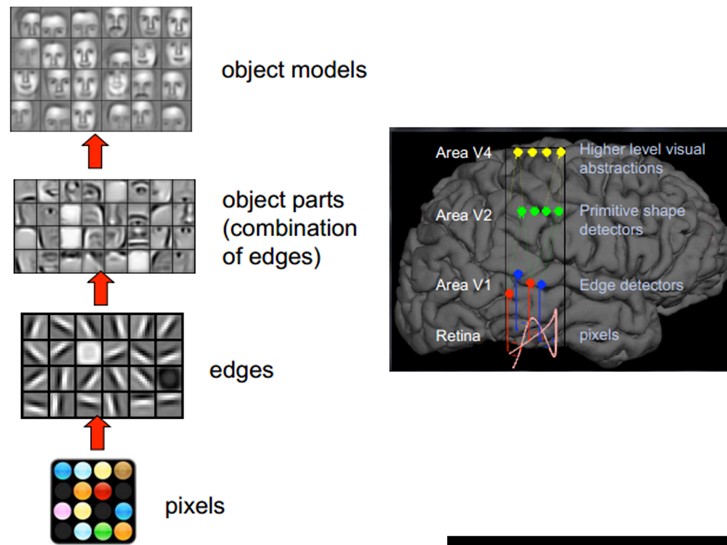 人类的视觉原理如下:首先我们的眼睛会接受像素信号,紧接着大脑的某些皮层细胞会识别出方向、线条等信息,接着就是脑部信息的判定,这些线条是组成了什么形状?最后大脑进行抽象判定,认为这是一个具体的某个物体。图2.1是人脑进行人脸识别的一个示例:
人类的视觉原理如下:首先我们的眼睛会接受像素信号,紧接着大脑的某些皮层细胞会识别出方向、线条等信息,接着就是脑部信息的判定,这些线条是组成了什么形状?最后大脑进行抽象判定,认为这是一个具体的某个物体。图2.1是人脑进行人脸识别的一个示例:
图2.1 人脑识别人脸过程
 即使物体的形状不同,但人类感知物体的过程几乎是相同的,都是大脑一步一步抽象判断的结果,如图2.2所示:
即使物体的形状不同,但人类感知物体的过程几乎是相同的,都是大脑一步一步抽象判断的结果,如图2.2所示:
图2.2 人脑对于不同物体的感知
由图2.2我们可以看出,底层的特征往往差别不大。在大脑没有进行抽象处理前,仅仅是几个线条,我们无法了解这个事物具体是什么。而越往上抽象分析,该事物的一些专有的特征就越明显。因此在大脑一次又一次的提取信息、抽象认知后,最终我们就能认识到这个事物。从而表现出人类可以区分不同的物体。
因此我们是否也可以模仿大脑的层层认知,构建一个多重认知的网络呢?低层仅仅认知初级的点线特征,每高一层就将上一层的信息整合分析,认知更加精确的特征,这样层层递进,在某一层就可以达到类似于人脑的认知程度。科学家这样的设想造就了今天的神经网络,也就是深度学习最核心的部分。
计算机科学家们受此启发,提出了深度学习的概念:深度学习是具有以下特点的机器学习算法,使用多层级联非线性处理单元用于特征提取和转换,每一层的输入都是上一层的输出;通过监督(分类)或无监督(模式识别)方式学习;学习对应于不同抽象级别的多级表示; 这些级别构成了概念的层次结构。
在图2.3所示的神经网络中,input layer和output layer分别为输入层和输出层,hidden layer为隐层。图中的神经网络是比较简单的神经网络示意图,但现在的深度学习发展的极其迅速,所以往往隐层的数量远远多于几十个。在深度神经网络中,层与层之间是递进的关系,每一层的输入都是前一层的输出,但也正如图2.3所演示的那样,层与层之间的递进也演变出了更加抽象的特征。
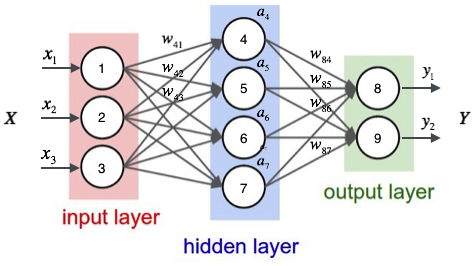
图2.3神经网络示意图
2.1.2深度学习常用模型
根据是否存在监督,可将深度学习模型分为两类:监督学习网络和无/半监督学习网络。所谓监督学习,就是由监督和学习组成。监督指的就是在深度学习的过程中,这个过程是受到监督的,其作用就是为了避免出现错误。当发生了错误后,由于有监督的存在,学习的方向会得到修正,避免向错误的方向发展下去
而学习就与我们日常所说的学习一样,在多次的学习后改正错误,从而学到正确的知识。因此监督和学习的配合会使得机器学习往高效正确的方向前进
本文采用的是有监督的卷积神经网络CNN,因此简单介绍一下有监督的神经网络。有监督的神经网络一般可分为2种:循环神经网络RNN和卷积神经网络CNN。
(1)循环神经网络(Recurreent Neutral Network)
当输入的样本信息为简单的物体时,卷积神经网络能够具有很好的识别效果。但是如果输入的样本要与时间联系到一起,即样本的输入会受到时间的影响时,传统的CNN模型效果就会差强人意,正如RNN名字所展示出的那样,一个层级的输出和上一层级的输出也有关,该网络会对前面处理的信息进行一个“记忆存储”,这就是RNN诞生的初衷。
如图2.4所示的层级展开图。与CNN不同的是对之前的信息处理会有一个记忆。在图2.4中,St表示样本在时间t处的记忆。
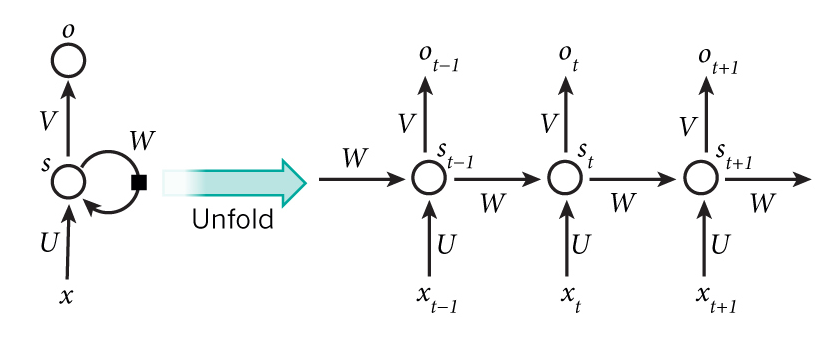
图2.4Hidden Layer的层级展开图
(2)卷积神经网络(Convolutional Neutral Network)
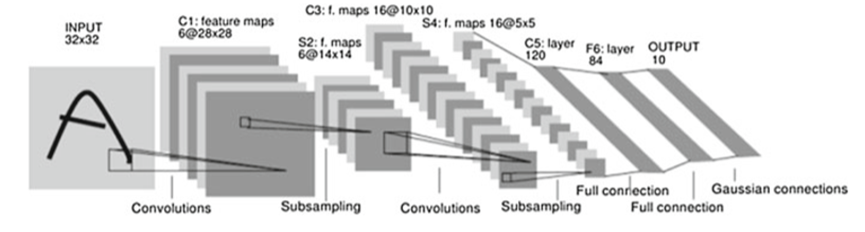 卷积神经网络之所以能够学习图像,其主要利用的是降维的思维,常见的CNN模型主要有AlexNet、VGGNet、ResNet等。但最早的CNN模型诞生于1994年,其设计者为卷积神经网络之父Yann LeCun。其网络结构如图2.5所示:
卷积神经网络之所以能够学习图像,其主要利用的是降维的思维,常见的CNN模型主要有AlexNet、VGGNet、ResNet等。但最早的CNN模型诞生于1994年,其设计者为卷积神经网络之父Yann LeCun。其网络结构如图2.5所示:
图2.5 Lenet网络结构图
Lenet是最典型的卷积网络之一,它虽然很小,但它同样包含了卷积层、池化层、全连接层。其中输入层统一将图片归一化为32*32。图2.5中的C1、C3、C5为卷积层,S2和S4为池化层。二者组成的卷积组逐层提取特征,最终通过F6和output的全连接层完成分类。
卷积神经网络保留了重要的参数,去除了不必要的参数,从而达到了更好的学习效果。而且与RNN不同,卷积神经网络中每个神经元不必再和前一层的所有神经元相连,因此减少了很多参数,权值共享也使得卷积神经网络参数的大幅减少。
2.2卷积神经网络
2.2.1 网络结构
卷积神经网络是有监督学习的神经网络,其参数相较于同为监督学习的RNN来说更少,输入与时间无关。其卷积层和池化层所组成的卷积组是卷积神经网络的核心部分[5]。该网络模型通过采用梯度下降法最小化损失函数对网络中的权重参数逐层反向调节,通过频繁的迭代训练提高网络的精度。卷积神经网络的低隐层是由卷积层和最大池采样层交替组成,高层是全连接层对应传统多层感知器的隐含层和逻辑回归分类器。第一个全连接层的输入是由卷积层进行特征提取得到的特征图像。最后一层输出层是一个分类器,可以采用逻辑回归,Softmax回归甚至是支持向量机对输入图像进行分类。
输入图像统计和滤波器进行卷积之后,提取该局部特征,一旦该局部特征被提取出来之后,它与其他特征的位置关系也随之确定下来了,每个神经元的输入和前一层的局部感受野相连,每个特征提取层都紧跟一个用来求局部平均与二次提取的计算层,也叫特征映射层,网络的每个计算层由多个特征映射平面组成,平面上所有的神经元的权重相等。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
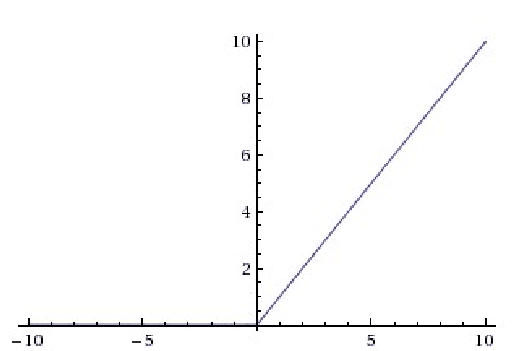
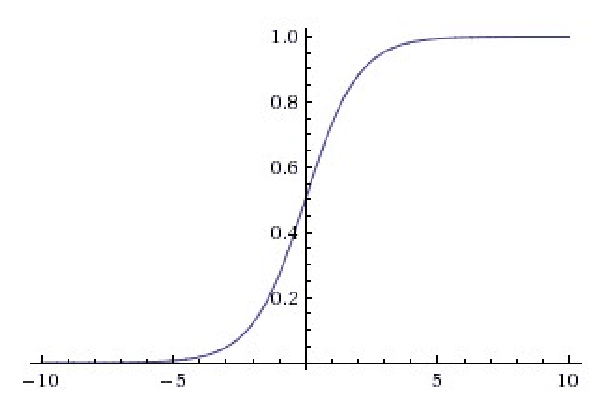
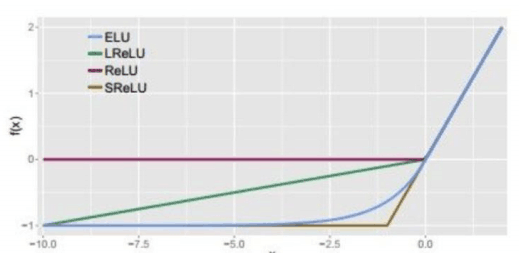
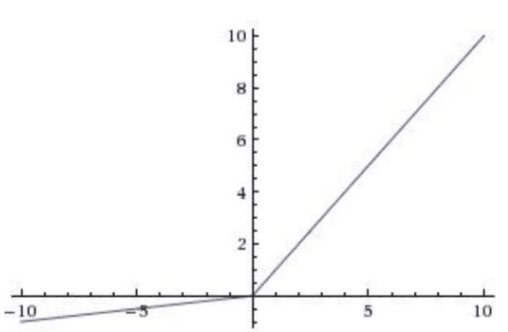
相关图片展示: