基于激光雷达和图像的电制动系统EBS系统研究毕业论文
2020-03-10 19:33:11
摘 要
障碍物检测技术作为AEB系统以及更高级别的智能驾驶、无人驾驶车辆的EBS系统的关键技术之一,是提高车辆安全性的重要措施。目前利用多种传感器进行信息融合来进行车辆周围局部环境感知的方案越来越受到认可,但针对这一领域的研究仍然不多,特别是图像和激光雷达的融合的研究较少。而单一传感器组成的系统在系统的稳定性和可靠性方面较弱,而且此类系统的测量维度和范围往往有限,面对复杂问题是获得的结果置信度较低且适应能力有限,而多传感器融合系统可以很好的解决这个问题。本文针对联合图像和激光雷达的EBS关键技术障碍物检测技术进行研究。
本文基于Python、计算机视觉库OpenCV和机器学习库TensorFlow搭建了障碍物检测算法框架,对基于机器学习的图像识别方法与图像的深度学习方法进行对比分析,同时针对单一传感器系统和多传感器融合系统进行了比较。
论文主要研究内容如下:
1、对比分析了基于HOG特征和SVM分类器的障碍物检测技术与图像的深度学习方法,即卷积神经网络的障碍物检测技术。
2、研究了卡尔曼滤波算法在解决目标遮挡问题中的应用。
3、设计了基于图像和激光雷达的障碍物检测技技术的融合方案,利用激光雷达为图像识别提供候选区域并对两个传感器得到的局部检测结果进行融合,并与单一传感器方案进行比较。
研究结果表明:深度学习方法在基于图像的障碍物检测中适应性、实时性更好,但依赖于大量数据进行训练。利用目标跟踪可以有效解决目标遮挡导致的错误检测问题。基于图像和激光雷达的障碍物检测技技术的融合方案相较于单一利用视觉系统的方案在计算效率上提升明显,得到的检测结果具有更高的置信度。
本文的特色:利用激光雷达在障碍物提前和测距定位方面的优势,为图像识别提供候选区域,避免了图像识别在目标假设生成阶段巨大的计算消耗,计算效率提升。
关键词:障碍物检测;图像;激光雷达;多传感器信息融合
Abstract
As one of the key technologies of AEB system and a higher level of intelligent driving and unmanned vehicle EBS system, obstacle detection technology is an important measure to improve vehicle safety. At present, a variety of sensors for information fusion to carry out local environment perception around vehicles is becoming more and more recognized, but the research in this field is still not much, especially the fusion of images and laser radar is less. The single sensor system is weak in the stability and reliability of the system, and the measurement dimensions and scope of such systems are often limited. In the face of complex problems, the confidence of the results is low and the adaptability is limited, and the multi-sensor fusion system can solve this problem well. In this paper, obstacle detection techniques for EBS and key technologies of joint images and lidar are studied.
Based on Python, computer vision library OpenCV and machine learning library TensorFlow, this paper builds the framework of obstacle detection algorithm, compares and analyzes the image recognition method based on machine learning and the depth learning method of the image, and compares the single sensor system and the multi-sensor fusion system.
The main contents of this paper are as follows:
1. The depth learning method of obstacle detection technology and image based on HOG features and SVM classifier, which is the obstacle detection technique of convolution neural network, is compared and analyzed.
2, we study the application of Calman filtering algorithm in solving the problem of target occlusion.
3. The fusion scheme of obstacle detection technology based on image and laser radar is designed. Using laser radar to provide candidate region for image recognition and fusion of local detection results obtained by two sensors, and compare with single sensor scheme.
The results show that the depth learning method has better adaptability and real-time performance in image based obstacle detection, but relies on a large amount of data for training. Target tracking can effectively solve the error detection problem caused by target occlusion. The fusion scheme based on image and laser radar's obstacle detection technique is better than the single visual system, and the result has higher confidence.
The characteristics of this paper: using the advantage of laser radar in the advance of obstacle and location of distance measurement, it provides the candidate area for image recognition, and avoids the huge calculation consumption of image recognition in the stage of target hypothesis generation, and the efficiency of computing is improved.
Key Words:Obstacle detection;Image;Lidar;Multi-sensor information fusion
目录
第1章 绪论 1
1.1 课题研究背景及意义 1
1.2 国内外研究现状 2
1.2.1 基于图像的障碍物检测技术 2
1.2.2 基于雷达的障碍物检测技术 4
1.2.3 多传感器联合识别研究 5
1.3 本文研究内容 6
第2章 基于图像的障碍物感知 7
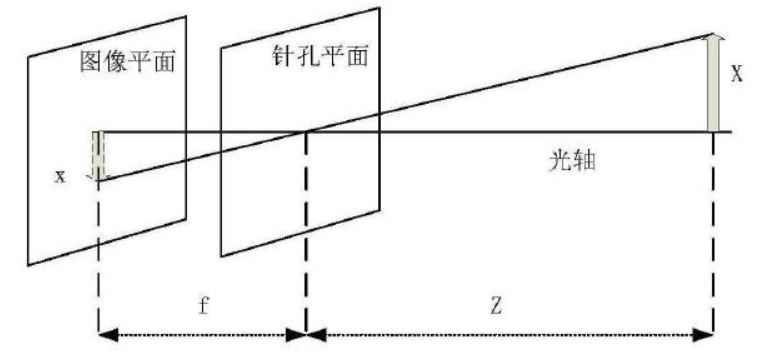
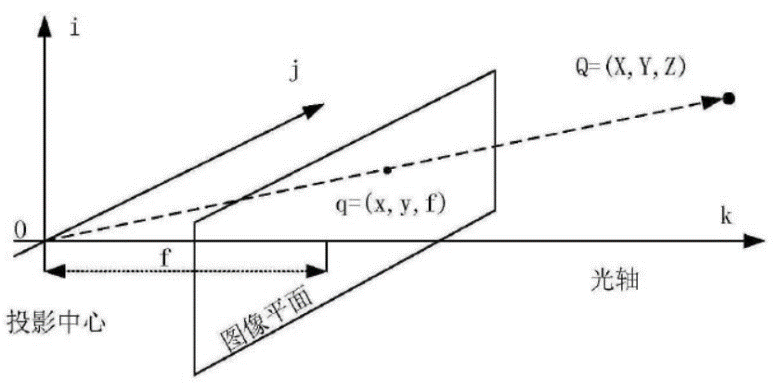
2.1 相机模型与相机标定 7
2.1.1 坐标系介绍 7
2.1.2 相机模型 8
2.1.3 相机标定 10
2.2 基于图像的障碍物检测 10
2.2.1 图像预处理 11
2.2.2 障碍物检测流程 13
2.2.3 生成假设 13
2.2.1 验证假设 15
2.2.2 深度学习方法 22
2.3 基于单目视觉的障碍物距离检测 23
2.4 障碍物图像跟踪算法 25
2.4.1 基于卡尔曼滤波算法的目标跟踪 25
2.4.2 基于数据关联的多目标跟踪 28
第3章 基于激光雷达的障碍物感知 30
3.1 激光雷达工作原理 30
3.2 激光雷达数据预处理 30
3.2.1 激光雷达数据表示 30
3.2.2 点云分割 32
3.3 基于激光雷达的障碍物检测 34
3.3.1 点云聚类分析 34
3.3.2 障碍物特征提取 35
3.3.3 结果判定 37
3.4 激光雷达障碍物跟踪 37
第4章 联合激光雷达和图像的前方障碍物识别算法研究 39
4.1 多传感器信息融合 39
4.1.1 多传感器信息融合原理 39
4.1.2 多传感器信息融合算法 40
4.2 激光雷达与图像数据匹配 42
2.2.1 时间上匹配 42
2.2.2 空间上匹配 42
4.3 联合识别算法研究 42
4.4 实验结果与分析 43
4.4.1 实验环境 43
4.4.2 图像障碍物识别效果对比 44
4.4.3 遮挡问题与目标跟踪 45
4.4.1 多传感器融合与单一传感器对比 45
第5章 总结和展望 46
5.2 总结 46
5.2 展望 46
参考文献 47
致谢 50
附件 51
第1章 绪论
本文围绕基于激光雷达和图像融合的障碍物检测技术的展开研究,研究成果可以应用于AEB系统以及更高级别的智能驾驶、无人驾驶车辆的EBS系统。
1.1 课题研究背景及意义
汽车给人们生活带来便利的同时带来了一些困扰,全世界因车祸致死的人已经远多于世界大战造成的死亡人数。制动系统作为车辆必须具备的总成之一,是实现车辆平稳、安全行驶的重要保证。随着汽车制动系统在技术上的不断进步,经历了漫长的发展后,相比元原来原始的设计方案,制动系统变得越来越成熟,可靠性大大提升。而且伴随着汽车电子技术的不断发展,车辆安全技术的发展趋势和研究重点逐渐向主动安全方向转移。
现有的成熟的主动安全技术如防抱死系统ABS与车辆稳定性控制系统ESC等,实现了在车辆可能发生失控的情况下仍然可以让车辆的响应跟随驾驶员的操作,有效避免了紧急制动时可能出现的方向失控与侧滑,制动效率得到了提升。而实际的情况是即便有了稳定性控制技术和传统的被动安全技术,事故仍然大量发生,研究发现根本原因在于驾驶员。UMTRI[1](密西根大学交通研究所)针对一系列交通事故的研究表明,驾驶员不正确的驾驶行为而引发的事故占据了事故总数的93% 。此外欧盟新车安全评鉴协会基于对交通事故的研究得出了类似的结论,约90%的交通事故是因为驾驶者分心或者未能集中注意力而导致的。而ABS和ESC作用的前提都是驾驶员采取了制动措施,并且假设驾驶员是理想驾驶员,即驾驶员的操作永远是正确的。但是很多情况下,在遇到突发情况时,分心或者一时疏忽,很多驾驶员根本来不及反应或进行制动,使得ABS和ESC并没有完全发挥作用,事故就发生了。
为了进一步提高车辆行驶的安全性,ADAS即先进驾驶辅助系统得到重视并快速发展,这类主动安全技术能够辅助驾驶员感知紧急情况并引导或帮助驾驶员采取紧急措施。AEB作为一种先进的EBS(电制动系统),是ADAS的重要一员。AEB可以在有极高的可能性会发生碰撞危险时,通过预先提醒驾驶员和必要时采取紧急制动的方式来避免发生碰撞或者达到减轻碰撞程度的效果。欧盟新车安全评鉴协会在2014年年初,将AEB加入评分系统,如果车型没有配备该系统将很难获得高星级的评价。
障碍物检测技术作为AEB系统以及更高级别的智能驾驶、无人驾驶车辆的EBS系统的关键技术之一,成为当前汽车安全辅助驾驶系统的研究的重要内容,对降低碰撞风险和提高车辆行驶的安全性具有重要意义。
1.2 国内外研究现状
通过查阅相关文献和对市场在售的商业化系统的调研,发现目前应用于车辆前方或周围的障碍物目标检测的常用传感器有利用采集图像获取信息的视觉传感器如摄像头,发射电磁波进行目标主动探测的雷达传感器如激光雷达和毫米波雷达,以及热源传感器红外传感器等。本文内容将围绕单一视觉传感系统和激光雷达感知系统,以及两者融合的感知系统展开。
1.2.1基于图像的障碍物检测技术
对驾驶者而言,驾驶汽车过程中以视觉感知周围环境为主,视觉图像包含的信息极其丰富,所以视觉传感器即摄像头在环境感知技术中应用十分广泛。摄像头价格便宜,可以区分物体颜色,包含着丰富的数据信息,但受光照影响大,测距不够准确,精度较低,障碍物识别的准确率依赖于算法。利用图像识别技术进行目标检测基于传感器数目进行区分,主要有单目视觉方案和采用两个及两个以上的双目或多目视觉两种方案。通过模仿人类立体视觉的形成方式,通过多目视觉系统可以实现三维重建[2],但多目视觉系统标定难度非常高,且对的算法的要求更高,价格也高出许多。
(一)基于图像的车辆目标识别
利用图像进行车辆障碍物的目标识别的方法可以总结为两个部分,分别是生成假设和验证假设[3]。
生成假设的目的是获取车辆在图像中可能存在的候选区域,从而减少验证假设的计算量,提升系统运行速度。基于先验知识、基于立体视觉、基于运动信息是生成障碍物候选区域假设常用的三种方法。基于先验知识[4]的候选区域获取方法通常利用汽车的一般特点,如汽车一般是对称的,汽车在颜色、纹理上的特点以及一些汽车特有的特征如车灯等。基于立体视觉[5]的假设生成的方法主要有两种方法,其中一种是视图差法,这种方法要求计算出每一幅图片的每一个像素点之间的关系和关联情况,然后根据计算结果对候选区域进行划分和提取,计算效率很低,对计算性能要求较高。另一种为逆透视映射法[6],这种方法利用了图像坐标系和世界坐标系之间的转换关系,通过把每个摄像头获取的图片通过坐标转换映射到同一个世界坐标系上,然后结合目标障碍物在每个摄像头视野下的偏差对目标对比和聚类并以此作为候选区域选择的依据。车载摄像头采集的视频数据背景的变化的,所以基于运动信息提取候选区域通常采用光流法。当摄像头与场景中的物体的相对距离发生变化,图像上的像素点会随之变化,光流法用光流表示这种运动。由于目标与背景会发生相对运动[7],结合采集的图像信息或者惯性传感器补偿摄像头自身的运动,再通过对时间进行差分就能够获取障碍物目标的运动信息。
验证假设的方法中,基于先验知识如模板匹配方法和利用机器学习方法是实际应用中普遍被认同和使用的方法。基于模板匹配的方法的基本思路是利用事先定义好的车辆类别的模板与生成的所有候选区域进行比较,匹配程度超过设定阈值的区域则定义为目标所在区域。基于机器学习的车辆障碍物检测方法需要事先对采集的图像进行特征提取,提取的特征描述为特征向量并要求包含目标对象的特征集合和非目标对象的特征集合,在训练分类器时需要加以区分,常用的特征有Haar特征、HOG特征、小波特征、SURF特征等。进行检测时直接使用训练好分类器进行检测,在车辆障碍物图像检测中常用的分类器主要有SVM、人工神经网络、Adaboost等。此外,很多学者通过融合多特征的方法获得了更好的检测效果。Lin[8]等人通过合并SURF特征和车辆边缘特征来对车辆特征进行描述,再利用分类器车辆分类与识别,得到了相比单一特征更好的检测效果。
近年来,随着深度学习的发展,在识别效果和速度上深度学习方法取得了很好的效果,已经成为车辆识别的重要研究方向。
(二)基于图像的行人目标识别
障碍物感知系统中,行人目标的感知是至关重要的,是提升行车安全的重要方面。国内外很多团队都致力于研究实时、准确的行人识别方案,形容识别算法可以分为三个部分:感兴趣区域获取、特征提取和分类。Papageorgiou[9]团队率先提出利用滑动窗口方法检测行人,再结合多尺度Haar特征和SVM分类器进行分类。Viola 等[10]通过引入积分图计算特征,计算效率提高,再通过AdaBoost算法完成行人特征的筛选和组合,并使用级联方式加快了检测速度。
针对行人目标的障碍物检测汇中,提取图像的梯度信息、外形轮廓信息以及运行信息等是使用较多的手段。基于梯度的特征提取方法在行人检测中使用广泛,基于SIFT 算子的灵感,Dalal等人提出利用梯度直方图[11] [11]对行人特征进行描述。HOG特征所获取的图像中的边缘梯度信息能够对行人目标的局部形状利用直方图的方式进行表示。由于HOG特征是在局部完成的特征提取,故当图片的几何形状或者光线发生变化时具有较好的不变性,对检测结果不会有较大影响。但是由于SIFT算子首先需要提取图像关键点,行人检测的效果并不理想。基于形状的行人特征描述的研究有很多,描绘全身形状较为复杂,通常利用人体局部轮廓的特征。Wu等人提出了利用图像EDGELET特征[13]来检测非动态图片中的行人的方法,提取特征后用adaboost算法对特征进行筛选,最终获得一组效果最佳的EDGELET特征对行人的整体进行表示。运动信息在行人检测中也得到了利用,光流法是针对运动相机进行动态物体识别的有效方法。
此外在2015年的IEEE国际机器人与自动化大会上,谷歌研究人员介绍了摄像头基于深层网络方法实现无人车的行人识别功能,效果非常出色。深度学习方法在行人检测中具有很好的应用前景。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: