窑异常状态监测和识别方法外文翻译资料
2022-09-29 10:14:00

英语原文共 8 页,剩余内容已隐藏,支付完成后下载完整资料
窑异常状态监测和识别方法
- 引言
在一个设备的运作过程中,要么是控制他们要么为了安全原因,一些过程变量需要被测量从而来监测其行为。在设备自动化系统中,这些变量会与他们计划的正常值相比,如果他们的值是超越了一些阈值,会给出控制或安全命令或产生警告警报。然而,设备的感应和自动化系统普遍的有许多不正常的情况不能识别。在这种情况下,知道设备应该怎样在一个正常的条件下运行的专家操作员可以检测到它的异常。由于这些异常情况的重要性,在一个完整的自动控制系统中自动的异常状态监测是必要的。
现代状态监测方法被引入去解决这些问题。有了这些方法,在一个设备的运作中就有可能预先地诊断和/或预测异常情况,以防止损坏设备或整个过程的崩溃。
在本文中,我们使用系统识别方法,以检测常见的异常情况下,在最重要的一部分的水泥厂,即水泥回转窑。要确定窑,我们使用LLNF模型,也被称为–Takagi Sugeno模糊模型[ 1 ]。局部线性模型树(LOLIMOT算法[ 2 ])是用于训练。在下一节中,介绍了回转窑的简要说明并讨论了一些可能发生的异常情况。此外,在文献中的其他技术,以应付水泥回转窑中出现的问题。此外,对上述输入输出选择的原因进行了讨论。在第3节讨论窑的输入通道延迟估计。为了这个目的,作者[ 6 ]提出的一种新的延迟估计方法被使用。在第4节中,以通过使用NNLF模型和LOLIMOT学习算法得到的模型为代表。在测试和验证中所观察到的三种异常情况的讨论在第5节中出现。最后,结论部分6。
- 水泥回转窑
水泥是由石膏和在一定比例的石灰石和粘土的混合物燃烧制成的水泥熟料研磨制成。水泥是用来约束其他物体在一起的。
输出水泥熟料的水泥回转窑是一个水泥厂的最重要的组成部分。在工厂里回转窑是一个长度约70米,直径约5米的圆筒,具有每天生产约2000吨熟料的生产能力。窑是由一个强大的电机带动旋转。在最热的内部的部分窑的温度高达1400摄氏度。
窑的工作不停,一个即将发生的故障最后可能会导致劣质的产品或者工厂一大部分的停机以及伴随着对设备不可挽回的损害。因此,使用一些方法以预防这样的故障和异常是必不可少。对水泥窑有不同的关注,并为每一个的他们提出并使用了不同的监测和控制方法。最重要的问题之一是关于窑的砖和外壳。窑内侧的砖是为了使窑壳获得超级热的一种保护。如果因为一些原因,有些砖块脱落或腐蚀,窑壳将会暴露在热材料中并且窑内的空气会容易的使那个地方的窑的形状变形。因为这个缘故,研究可能会损坏窑砖的条件成为了一个令人感兴趣的话题。小松和宇川研究不同材料和条件对砖的腐蚀的影响[ 3 ]。不断地控制窑壳的温度是另外一种多年来一直在水泥厂使用的方法。用红外系统测量窑壳温度是传统的方法。窑壳温度的监测也是文献中的一个令人感兴趣的话题。Torgunakov作为这个过程的3D模拟代表[ 4 ]。建立于此基础上他给出了一个窑的温度的定量描述,并试图消除窑壳上识别出的缺陷。由Stephan等人[ 5 ]提出并验证的利用微波辐射计测量窑壳温度是一种新的方法。微波与红外的优势在于前者相比于后者是相当少被灰尘散射-这在水泥厂是不可避免的。然而,这种方法仍然面临着一些问题,如绝对校准。
通过一组传感器,可以直接检测出窑内的超热表面和许多其他的异常情况,并由工厂自动化和安全系统报告。可以直接测量的其他变量是旋风分离器的高温,液压系统中的压力不足等。然而,有其他不可被常规自动化系统检测的异常情况。在这种情况下,一个单一的传感器不能通知我们有关过程的故障。这可能在所有的测量值都是在合理的范围内时发生,但工厂的整体行为是不正常的。一个专家操作员可以通过工厂当前的行为与预期的正常状态的行为相比较来识别这些状况。在本文中我们关注的是这些类型的故障或异常所导致的低劣的产品或是在过程中停止的起源。例如,一些发生在窑内的常见的异常:
●涂层崩解。
●铃声。
●超高温或超冷冻。
在本文中,我们使用系统识别方法来检测异常状态。超加热或超冷冻的问题是我们通过代表正常状态的窑的模型特别尝试检测的。该模型的输出是由带动回转窑旋转的电机消耗功率。输入是窑速度,原材料的进料速度,燃料供给率,二次空气压力和引风机转速。这一选择的原因是在这一问题上工厂的咨询专家和工艺工程师的结论。它被认为电机的消耗功率说明了窑的内部条件,因为它包含电机的电压和电流变化。并且以前提到的输入是它实际的变量。通过选定的输入和输出的方法,我们将开发一个表示窑的正常状态的模型,所以它将是有可能实现这个过程是进行的很好,还是什么不良正在发生。
萨维白水泥公司有着先进的方法。这家工厂每天生产大约500吨白水泥。我们使用在设备的运作期间所收集的过去的数据,并且没有任何干扰优化它的状态监测。因此,当一个不正常的情况发生时,操作员将检测到它,并作出适当的反应去解决这个状况。这意味着一个不正常的状态会停留的时间是非常短的,我们必须在这短短的一段时间内检测到它。
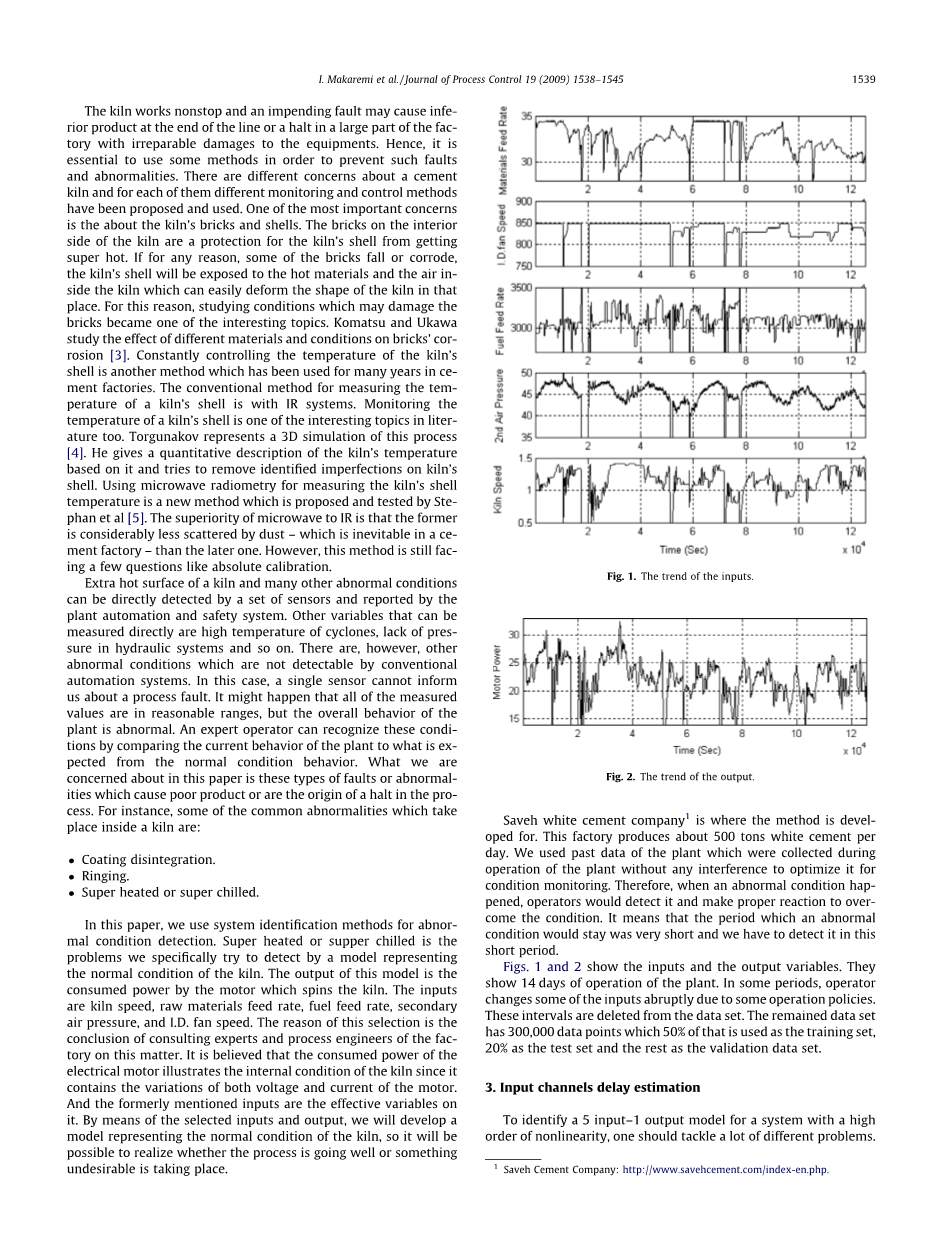
图片1和2显示输入和输出变量。他们显示了设备14天的运作。在某些时期,由于一些操作策略,操作员突然改变一些输入。这些区间从数据集合中被删除。所保留的数据集有300000个数据点,其中50%个被用来作为训练集,20%的测试集和其余的验证数据集。
- 输入通道延时估计
对于一个具有高阶的非线性的系统,去确定一个5输入-1输出的模型,应该解决很多不同的问题。估计输入通道的延迟和模型的输入和输出的顺序是在计算模型系数计算之前的主要问题。在同一时间处理所有的这些问题使搜索空间极大地巨大化,这样找到一个最佳的模型变的几乎是不可能的。因此,替代的方法可以确定一些剩余的独立的参数可以非常有帮助的减少搜索空间维度。这有助于找到一个找到最佳的模型的更平滑的问题。在这一节中,在处理与确定一个窑的模型之前我们尝试用一个无模型的方法来估计输入通道的延迟。
我们使用的方法是基于Lipschitz数[ 6 ]。他和浅田为阶估计开发的Lipschitz方法[ 7 ]。后来,作为顺序测定方法[ 8,9 ]这种方法已被用于文学和与其他替代品比较,以及也提高[ 10 ]对噪声的稳健性。然而,在所有提及的情况下,它已被假定输入通道的延迟是已知的。这是第一次,Lipschitz定理作为媒介被用来确定在[ 6 ]中输入通道延迟。此方法被解释在以下和它在估计输入延迟信道延迟的说明性的例子展示了它的能力。之后,将其应用于窑的输入输出数据的结果被体现。
3.1、基于Lipschitz数字延迟估计
这种方法是基于Lipschitz定理,其指出每个连续映射有有界限的梯度,且该界限可以利用在已知点梯度的最大值估计出。因此,这一想法可以使用,如果它是假设输入和输出之间的关系是一个光滑的地图,这在任何黑盒子的非线性系统辨识是一个强制性的假设。该算法如下[ 6 ]:
(1)假设y={y(KT)|k=1,...,N}是输出集,x={x(KT)|k=1,...,N}是输入集,其中T是取样时间。同样假定xd={xd(KT)=x((k-d)T)|k=d 1,...,N}是输入设置延迟的d样本。为了简单起见,T不会在其他的方程中显示。Lipschitz方法是对输出集进行设置以及一个延迟输入集{xd|d=1,2,...,D}的D成员超级集,这里面D是一个任意数。Lipschitz商数和Lipschitz数分别用(1)和(2)计算:
其中LN(K)是在所有Lnij和p之间大约是N的百分之1或2包括更多的输入延迟的第k个最大商,Lipschitz数减少并最终包含其所有相关的动态,之后这一数字将不会显著降低(图2A)。那个断点发生的地方(第d0次延迟),包括所有相关的动态。在这里D的选择是很重要的。如果太小,我们可能无法看到断点。同样,选择一个不合理的大的会使我们负担很多不必要的计算。
(2)第二步,以相反的方式,Lipschitz商数和数字应该被计算为D0–成员延迟的输入集的超集,{xd|d=1,2,...,D}。为此,第d次延迟的商用(3)计算,Lipschitz数用(4)获得:
正如我们看到的,方程(3)及(4)分别与(1)和(2)略有不同。为了计算Lnij,超集{xd|d=1,2,...,n}参与计算LBnij,超集{xd|d=1,2,...,D0}被使用。在第一部分中,从一个样本输入延迟开始,更高延迟的输入一个接一个的增加,看它们对Lipschitz数的影响。在第二部分,包括所有的延迟输入,他们被一个接一个从较低的延迟去除。因此,如果工厂有一个输入通道延迟表明在aT秒,然后除去n<a的延迟输入不会很大的影响Lipschitz数级。然而,去除第a次样品是Lipschitz数突然增加的原因。图3b显示在这一部分被计算的动态的Lipschitz数。第一次突然增加发生的地方被称为延迟。
3.2、举例说明
模型中使用的延迟估计方法被给出(5)。
在这个离散模型(T= 1),输出动态对输出的下一个样本有一个非线性的影响。然而,输入动态线性地影响输出。输入影响输出的特定字符是7个具有时滞的输入具有最高的系数并且第一和最后的输入动态有延迟5和9的延迟且具有最小的系数。因此,有可能该方法错过了第一个延迟,因为下一个延迟有较大的系数。为了获得该模型的输入和输出数据集,建立于此基础上产生的随机脉冲序列作为被计算出的输入和输出。计算程序的第一部分的Lipschitz数被计算出显示在图4。该图中的断点为15。因此前15的延迟的输入{xd|d=1, 2,..., 15},已用于该计算程序的第二部分。执行第二部分的结果如图5所示。从计算中删除第五秒的延迟输入后,输入通道延迟有一个显而易见的突然提高。
为了更具说明性的例子和一些其他的延迟估计方法比较,见[ 6 ]。
3.3、回转窑的输入通道延迟估计
在这部分中,在窑的输入-输出数据上我们采用了延迟估计方法。在下面,对五个配对的输入与输出的结果进行了介绍。图6-10显示了这个计算程序的结果。
表1总结了我们可以从这些图中获得的信息。结果是非常接近专家所指出。例如,一旦一个命令被给去改变材料的进给速度,它需要花费约十分钟使材料进入窑,并影响电机的消耗功率。正如表1所述,在图6中所示,该方法所计算的输入延迟是13分钟。作为另一个例子,当窑速度改变时,其功率马上变化,即它们之间没有延迟。此外,根据图8和表1,估计的输入延迟是零。
- 识别
知道输入通道的延迟,识别的搜索空间缩小,从而确定每个输入和输出的顺序变得更加容易,并以近似的最佳功能代表窑的运转状态。
我们使用LLNF网络识别窑的正常条件和LOLIMOT算法寻找最佳的网络结构和参数。在下面,对LLNF模型和LOLIMOT算法作了简要介绍,然后使用他们对窑的鉴定结果被表示出。
4.1、局部线性神经模糊模型[ 2 ]
非线性系统识别的著名的结构之一是LLNF网络。在这一结构中的每个细胞都包含一个线性模型,他的有效性是基于隶属函数。这些标准化的隶属函数可以是任何类型(图11)。此外,归一化高斯函数用于简单类型:
这里u=[u1u2...up]是先前输入的矢量。要确保所有的局部线性模型的贡献总结为单位,(6)必须被包含。每个神经元的线性模型的输出是
并据此对LLNF模型输出被代表通过
因此,网络的输出是局部线性模型的加权输出。换句话说,网络可在局部线性模型之间与验证功能之间插入间隔。
这个网络有几种学习算法。LOLIMOT是可以非常有效地找到合适的结构模型和参数估计算法的其中一个。
4.2、LOLIMOT算法[ 2 ]
LOLIMOT是一个渐进的树结构算法将输入空间相对于它的正交轴隔开。在每一次循环中,在模型中加入一个新的规则,它代表一个局部线性模型。该算法使用一个分层的方法,用于生产结构,并避免了非线性优化算法。由此产生的规则通过加权最小二乘法进行了优化。
该算法是由一个外环的回路去确定结构和一个嵌套的内部的回路用于优化规则的参数,这使得它成为一个五步算法:
(1)以一个通过确定神经元数量的初始模型开始。在M = 1的情况下,网络只是一个简单的线性模型。
(2)在M线性模型中,一个具有最差的性能,应该通过I被选择和索引出,这个性能可以用(9)计算出:
- 在这一步中,在对应的第L个线性模型的子空间的所有维度的所有分裂的部分应该被尝试。分部数等于输入空间的维数(P)。
- 对于这些P的替代品,具有最小损失函数值的一个应该被选择。(M→M 1)。
(5)如果要满足终止条件,要走2步。
图12演示了LOLIMOT算法中的分裂过程。
4.3、窑识别
我们用NNLF网络和LOLIMOT学习算法识别窑。在识别过程中,有一些问题我们不得不处理。似乎,每一个输入都有其特定的影响在输出上持续。例如,材料供给到窑中的约30分钟。此外,窑内温度的变化,这是改变燃料流量和二次风持续约20分钟的结果,窑速变化的影响对电动机的消耗功率可能不超过2或三分钟。考虑到这一事实,所有的动态过程中,每一个输入影响的输出应采取在使用
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[150309],资料为PDF文档或Word文档,PDF文档可免费转换为Word



