基于数据挖掘的异常电力用户预测系统设计毕业论文
2020-02-18 11:06:56
摘 要
随着大数据时代的到来,我国电网发展逐步趋向信息化。《中国电力大数据发展白皮书》中指出,新时代的智能电网建设,数据驱动的电源供应链注定将取代传统的电力供应链。现有的用电信息采集系统的广泛使用,电力企业积累了体量巨大的电力数据,而其中异常数据蕴藏着重要的电网事件信息。将数据挖掘技术引入,在海量数据中进行提炼,进行有效的异常预测,会大大提升我国电力部门信息平台承载能力和业务应用水平。
本文设计的基于数据挖掘的异常电力用户预测系统,结合电力数据本身的有序性和周期性,使用常规日负荷曲线作为异常预测的指标性状,使用一种基于 KNN的快速密度峰值异常预测算法。快速密度峰值聚类算法在对异常电力用户预测时,忽略了数据的局部特征,局部密度取决于截断距离的主观选择。利用K-Nearest Neighbors(KNN)思想重新定义局部密度和距离,并设计判断异常值的规则,优化了原始算法,改善其不足,实现更加准确的异常电力用户预测。基于南京市24点网供及地区负荷数据的异常预测仿真实验证明了该算法的有效性。
关键词:数据挖掘;异常电力用户预测;KNN;快速密度峰值聚类算法
Abstract
With the advent of the era of big data, the development of China's power grid has gradually become informational. The "China Power Big Data Development White Paper" pointed out that in the new era of smart grid construction, the data-driven power supply chain is destined to replace the traditional power supply chain. Due to the widespread use of electricity information collection systems, power companies have accumulated huge amounts of power data, and the anomaly data contains important information on grid events. The introduction of data mining technology, refining in massive data, and effective anomaly prediction will greatly enhance the carrying capacity and business application level of China's power sector information platform.
The data mining-based anomaly power user prediction system designed in this paper combines the order and periodicity of power data itself, and uses the conventional daily load curve as the index trait of anomaly prediction. A fast density peak anomaly prediction algorithm based on KNN is used. The fast density peak clustering algorithm ignores the local features of the data when predicting abnormal power users. The local density depends on the subjective choice of the truncation distance. Using K-Nearest Neighbors (KNN) idea to redefine local density and distance, and design rules for judging outliers, optimize the original algorithm, improve its deficiencies, and achieve more accurate abnormal power user prediction. An anomaly prediction simulation experiment based on 24 points network supply and regional load data in Nanjing proves the effectiveness of the algorithm.
Key words: data mining; abnormal power user prediction; KNN; fast density peak clustering algorithm
目录
摘要 i
Abstract ii
第1章 绪论 1
1.1研究背景及意义 1
1.1.1 研究背景 1
1.1.2 研究意义 2
1.2 国内外主要研究现状 2
1.3 主要的设计研究 4
第2章 基础理论研究 5
2.1 数据挖掘概念介绍 5
2.2 聚类算法研究 7
2.2.1 K-Means算法 7
2.2.2快速密度峰值聚类算法 8
2.2.3 算法比较 9
2.3 KNN算法概述 9
2.4 小结 10
第3章 KNN优化快速密度峰值异常预测 11
3.1 异常预测算法 11
3.1.1 以距离为参考指标的异常预测算法 11
3.1.2 以密度为参考指标的异常预测算法 11
3.1.3 以聚类为方法的异常预测算法 12
3.2 KNN优化的快速密度峰值异常预测 13
3.2.1 算法描述 13
3.2.2 异常参考标准值 14
3.3 实际数据的仿真实验 14
3.3.1 数据描述及标准化 14
3.3.2 南京市24点负荷数据异常预测 14
3.4 小结 18
第4章 异常电力用户预测系统 19
4.1 异常电力用户预测系统的设计目的 19
4.1.1 系统功能需求 19
4.1.2 系统功能使用说明图 19
4.1.3 系统性能指标 20
4.2 系统总体设计 21
4.2.1 软件运行环境 21
4.2.2 系统架构图 21
4.3 系统功能模块设计 22
4.3.1 模型调用过程 23
4.3.2 仿真系统运行 23
4.4 小结 24
第5章 总结与展望 25
5.1 总结 25
5.2 展望 25
参考文献 26
致谢 27
第1章 绪论
1.1研究背景及意义
- 研究背景
信息化大数据时代已经悄然来到,不仅是互联网、通信行业,各个行业都受到大数据的冲击[1]。对电力行业而言,大数据也蕴藏着重要的事件信息,带来挑战的同时,也带来了机遇[2]。 目前,智能电网的建设不断推进,SG186、SG-ERP信息化工程已经建设了众多信息系统和平台,电网企业已经积累体量巨大的电力数据。 不对成指数增长的用电数据及时处理,就会造成“数据灾难”,同时如何挖掘这些数据,让数据资产产生真正的价值也是电力企业亟待解决的问题[3]-[5]。
在早期,我们主要通过定期检查、电表的现场校验、用户窃电举报等手段来发现异常电力用户, 人力依赖性强、目标散漫、考核困难,更谈不上对异常预警,挽回不必要的电量损失。目前,随着电力信息采集系统的普及,系统计量异常报警功能和电力数据查询功能可以实现对用户用电情况的在线监测。 通过收集异常电源,负载异常,终端告警,主站告警,线路丢失异常等信息,实现用户电源异常的在线识别。这种方法比传统识别用电异常有所提高,但是这些检控和识别也依赖于大量的供电单位营销稽查人员、用电检查人员和计量人员,对业务水平和人员的专业水平有一定的要求。 还有就是误报率过高,无法达到真正快速精确定位异常用电用户的目的,并且工作人员在处理上具有很大的主观性, 存在明显的缺陷,所以实施效果往往不尽如人意,且不具备可持续性。
表1.1 北京地区三月份用电信息采集系统的异常类型及其数量
以北京电网为例,电力信息采集系统每天将收集780多万条电能数据,每月异常报警将达到120万条。如表1-1所示,电力信息采集系统的现有数据密度太低,无法有效支持管理和运营决策。基于数据挖掘,发现电力数据异常的更深层次规则,消除数据的偶然性和精炼数据的必要性。让电量损失能预警,得以减损增效,降低电力企业的运维投入,进入真正的智能电网时代。
- 研究意义
异常电力用户的预测是建设智能电网必不可少的一步,其主要的研究意义有以下四点:
- 推动电力行业业务转型。传统的电力业务模式以电网物理模型为核心,不符合市场个性化的需求和时代发展要求,需要转向基于数据信息相关性的大数据业务模型的高效且低成本的可持续方法。
- 提升经济效益。 如果能有效提取异常用电数据背后的数据规律,降低误报率,主动发现异常,提前进行处理,就能为电力企业节支增收,降低甚至避免电力企业因为电能装置异常或用户异常用电导致的经济损失,也能对有窃电行为的用户进行电费追补和违约用电处罚,对民众形成有力的震慑,有效降低运维线损,提升企业强力形象和经济效益。
- 增强管理水平。 运用大数据预测技术,多维度地综合用电信息、表计状态、异常报警、线路线损等数据信息,快速定位异常电力用户,系统化定期开展计量异常/反窃电分析、预警、排查和处理工作, 合理调度维护人员,形成闭环管理机制。
- 提升企业形象。以客户为中心,让数据明细公开化,提炼异常数据所蕴藏的深层次原因,避免“数据灾难”和“数据荒废”。对电量计量装置的异常,及早发现处理,保证电费计量的准确稳定可靠,加快智能电网建设。
1.2 国内外主要研究现状
大数据的时代已经到来。电力行业已经有了不少基于数据挖掘的研究和开发项目[6]。在国外,美国电力学会(EPRI)启动了智能电网大数据研究项目,PGamp;E以用户电力数据为主要数据来源开展大数据应用研究。在中国,2013年3月,中国电工学会电力信息委员会编写并出版了《中国电力大数据发展白皮书》。这本书里解读电力大数据的内涵,介绍了特征,阐明了大数据背后隐藏的价值。
异常预测是数据挖掘的一个重要的方面,现在的智能电表和用电信息采集系统提供了必要的数据基础,但在实际的运维中还是采用传统的简单阈值判定来预测异常电力用户。目前,大数据的异常预测的方法主要有,以统计为方法的异常预测、以聚类为方法的异常预测、以分类为方法的异常预测、以近邻模型为方法的异常预测等。作为一种广泛使用的数据挖掘方法,聚类实现了高效地发现特征预测异常。 它逐渐被应用于智能电源领域。与同样作为常用数据挖掘算法的分类相比,不需要提前分类的聚类算法更适应复杂的电力使用行为。以聚类为方法的异常预测,判断不属于任何类别的样本点或者离群集中心过远的点为异常点。但是通常有一个缺点,即其时间复杂多数为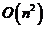 ,而没有针对性的数据优化改良,因此现有的常规基于聚类的异常检测性能并不好。
,而没有针对性的数据优化改良,因此现有的常规基于聚类的异常检测性能并不好。
目前,在数据挖掘的基础上,国内外专家针对异常电力用户预测问题提出了新的思路和解决方案。如下图1-1。
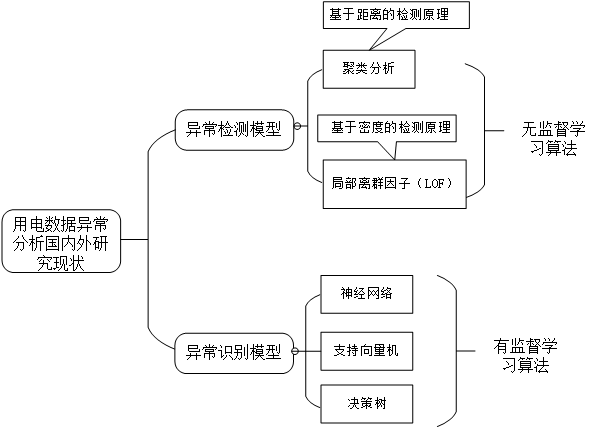 图1-1国内外电力数据异常研究现状分析示意图
图1-1国内外电力数据异常研究现状分析示意图
目前,国内外有各种异常值检测算法以及改进算法,但都存在一定局限性,因此需要结合不同类型异常值检测算法, 寻找更优法,设计一个更准确更高效的异常预测系统。
1.3 主要的设计研究
本文主要要设计基于数据挖掘的异常电力用户预测系统,可以明确,基于数据挖掘的 异常用电数据预测对智能电网的建设、推动电力企业转型、提高资源利用、发挥数据资产价值都有着重要意义。本文主要将从以下几个方面进行系统设计研究。
- 简单阐述数据挖掘的理论方法和基本过程。在数据挖掘技术众多方法中,选用聚类分析算法,进一步说明KNN优化的快速密度峰值异常检测算法的理论方法。
- 基于KNN的快速密度峰值异常值检测。基于基本理论方法,在实际工作过程中改进了有效的离群检测算法。针对传统的基于距离,基于密度,基于聚类的离群点检测的局限性和不足,基于快速密度峰值聚类算法,提出了一种基于 KNN的快速密度峰值异常检测算法。 该算法克服了原始快速密度聚类算法的不足,不考虑数据的局部特征和截断距离的依赖性,并从异常检测的角度对其进行优化。 并进行仿真实验得到较好的异常预测效果。
- 异常用电数据预测系统需求分析和总体设计。主要介绍功能模块设计,针对每个模块详细介绍了设计思路和实现方法,以及对数据进行系统仿真,基本满足了设计需求。
第2章 基础理论研究
由于电力大数据的多样性和复杂性,现有的电力信息系统难以满足深远的数据处理及研究,因此引入了数据挖掘技术,利用统计学和机器学习建模的背景知识构建智能电网。 本章主要介绍了数据挖掘技术,及其在实际电网中常运用的方法,并详细介绍了K- Means算法和快速密度峰值算法,分析比较这两种算法的优缺点,再介绍了一下KNN思想,为下一步的算法的优化和系统设计的研究打下基础。
2.1 数据挖掘概念介绍
数据挖掘(Data Mining)的定义是在不完全的、有噪音的、模糊的、随机的庞大数据中,找到尚且未知的、具有价值的事件信息的过程[7]。大数据是隐形的资产,数据挖掘可以处理结构化的、半结构化的、和非结构化数据。数据挖掘是不同学科的交集。围绕跨学科技术开展交叉创新不断迎来数据挖掘领域创新高潮。
1999年欧盟等机构一起商议起草了数据挖掘在工业上的一种标准过程CRISP-DM(Cross-industry Standard Process for Data Mining),即“跨行业数据挖掘标准流程”。CRISP-DM代表整个行业的数据挖掘标准流程,并为数据挖掘行业形成统一的规范。CRISP-DM模型为KDD项目提供了完整的流程描述,将KDD项目流程划分为6步,即:商业问题(Business Understanding)、数据理解(Data Understanding)、数据准备(Data Preparation)、建模(Modeling)、评估(Evaluation)、开发(Development)。图2-1展示了CRISP-DM模型。在实际应用中,各个阶段的顺序不是绝对不变的,各个阶段一定会有反复的过程。
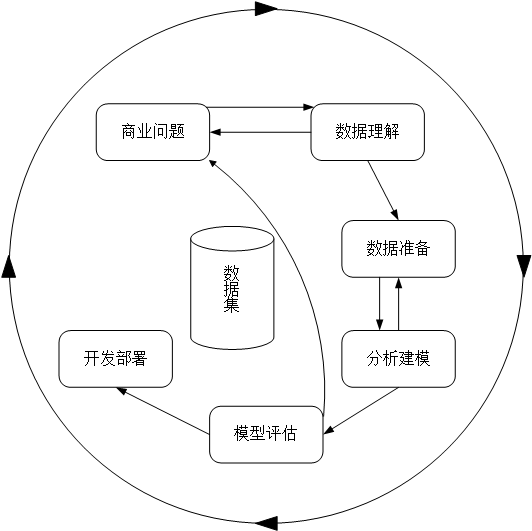
图2-1 数据挖掘的过程
数据挖掘常用于电网中的方法有:
- 聚类与分类算法
聚类分析是根据相似性和差异性将一组数据分成几个类别。聚类分析是根据相似性和差异将一组数据分成几个类别。让不同类别的数据之间的相似性达到可行的最小。分类主要思想是用数据库中一组数据对象的共同特征将它们分成不同的类。训练好的分类模型把数据库中的数据项映射到给定类别。
- 统计分析方法
用于发现因变量与一个或多个自变量之间的关系。可以用数据的时间特征来构成函数,用实值预测变量。用于回归模型的负荷预测、基于贝叶斯算法的用户分类、基于方差的误差检测等。
- 决策树
决策树是在各种情况的发生概率基础之上,使用构造决策树,确定净现值的期望值大于或等于零的概率。用于评估项目风险并判断其可行性的决策分析方法是直观地应用概率分析的图形方法。常与神经网络相结合进行电力系统在线安全评估,可以进行在线预测动态安全性。
- 时间序列模型
时间序列模型常用于短期负荷预测,但存在局限性,要求计算体量不大,不能处理气象因素的影响。
2.2 聚类算法研究
2.2.1 K-Means算法
K-Means算法[8],也称为K-均值或者K-平均,它是一种经典的划分式聚类算法。该算法的目标是寻找的聚类群集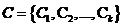 最小平方误差式(2-1)的过程:
最小平方误差式(2-1)的过程:
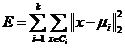 (2-1)
(2-1)
公式中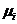 是群集
是群集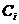 的均值向量,或者被称为质心,其表达式为
的均值向量,或者被称为质心,其表达式为
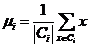 (2-2)
(2-2)
其算法思想大致为:首先从样本集中随机选择一个样本作为聚类中心,然后计算所有样本与该“聚类中心”之间的距离。 对于每个样本,将其划分到最靠近它的“群集中心”所在的群集中。将显示一个新群集,并计算每个群集的新“群集中心”。
根据以上描述,实现K-Means算法的主要三点:
- 群集个数的选择
- 各个样本点到“群集中心”的距离
- 根据新划分的群集,更新“群集中心”
K-Means算法具有许多优点,实现相对简单,计算效率也高。 当面对差别不大的球形簇时,该算法有很好的表现。但与此同时,该算法也有其缺点。首先,很多时候需要事先知道数据集会划分为几类,而这个划分规律不是很明确。其次,算法对异常数据十分敏感,其在计算聚类中心的过程中,如果某个数据偏离正常值的程度较大,会对结果有非常大的影响。
2.2.2快速密度峰值聚类算法



