基于稀疏自动编码器的非监督特征学习毕业论文
2020-02-19 09:51:16
摘 要
随着互联网行业的兴起,人工智能成为当前发展的新潮流,机器学习与深度学习是目前人工智能领域的主要技术手段,在图像识别与分类,视觉及语言等各个领域都有着广泛的应用并取得了良好的效果。然而,随着数据的繁杂程度越来越高,大量的冗余信息同主要特征混杂在一起,极大地增加了时间与空间的复杂度且降低了分类结果的精确度。在处理这些高维数据时,经典的传统数据降维方法已经无法取得较好的效果。因此,本文采用了基于稀疏自动编码器的方法来进行非监督的特征学习。通过构建稀疏自动编码器得到原始数据集的稀疏表达向量,将学习到的深度特征接入分类器,通过比较识别的准确率来评价降维的效果。实验的结果表明:基于稀疏自动编码器的降维算法与其他经典的降维方法相比总体精度更高,证明了对于高维数据,稀疏自动编码器能更好地进行非监督特征学习。
关键词:深度学习;稀疏自动编码器;非监督学习;数据降维
Abstract
With the rise of the Internet industry, artificial intelligence has become a new trend in the current development. Machine learning and deep learning are the main technical means in the field of artificial intelligence. They have been widely applied in various fields, such as image recognition and classification, vision and language, and have achieved good results. However, with the increasing complexity of data, a large amount of redundant information is mixed with main features, which greatly increases the complexity of time and space and reduces the accuracy of classification results. In dealing with these high-dimensional data, the classical and traditional methods to reduce the dimension of data cannot achieve good results. Therefore, this study adopts the method of sparse autoencoder to conduct unsupervised feature learning. First, by constructing sparse autoencoder, we can obtain the sparse expression vectors of the original data set. Then connecting the learned depth features into the classifier. Finally, by comparing the accuracy of recognition, we can evaluate the effect of dimension reduction. The experimental results show that the dimension reduction algorithm based on sparse autoencoder has higher overall accuracy than other classical dimension reduction methods, which proves that sparse autoencoder can perform better in unsupervised feature learning for high-dimensional data.
Key words Deep Learning; Sparse Autoencoder; Unsupervised Learning; Dimension Reduction
目 录
第1章 绪论 1
1.1 课题研究背景和意义 1
1.2 国内外研究现状 2
1.2.1 非监督特征学习研究现状 2
1.2.2 自动编码器研究现状 3
1.2.3 数据降维研究现状 5
1.3 本文研究主要内容 6
第2章 经典降维算法 7
2.1 维数灾难 7
2.2 线性降维算法 8
2.2.1 主成分分析(PCA) 8
2.2.2 线性判别分析(LDA) 8
2.3 非线性降维算法 9
2.3.1 等距映射(ISOMAP) 10
2.3.2 局部线性嵌入(LLE) 10
第3章 特征提取 12
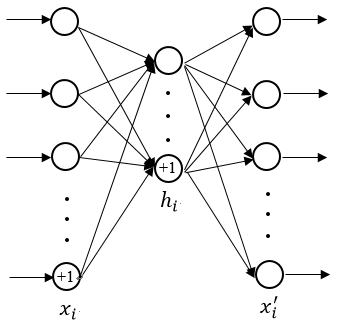
3.1 多层前馈神经网络 12
3.2 反向传播算法(BP算法) 13
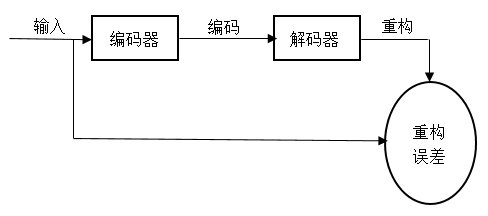
3.3 自动编码器 14
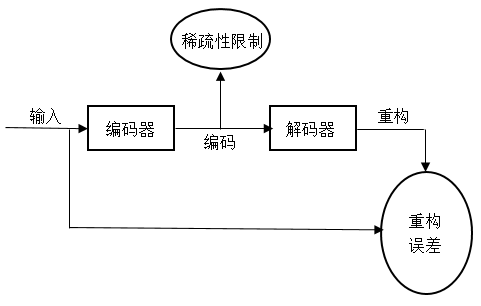
3.4 稀疏自动编码器(SAE) 16
第4章 降维实验 18
4.1 实验环境 18
4.2 实验数据 18
4.3 实验结果与分析 19
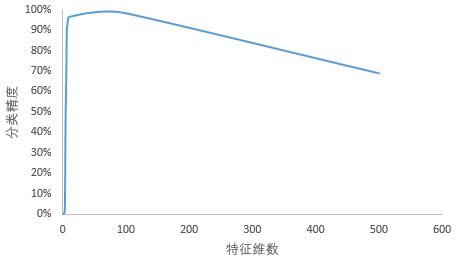
4.3.1 特征维数对SAE降维效果的影响 19
4.3.2 SAE与传统降维方法比较 20
第5章 总结与展望 21
参考文献 22
致谢 24
第1章 绪论
本章介绍了关于课题的相关研究背景以及研究意义,对非监督特征学习、自动编码器以及其他数据降维方法的起源、发展和近年来国内外的研究现状做了归纳与总结。最后阐述了本文的主要研究内容。
1.1 课题研究背景和意义
随着科技的高速发展,互联网作为一颗新星进入我们的世界,人们的生活也因此变得越来越非富多彩,琳琅满目的信息络绎不绝。古有学士云游四海而求教,现在的人却能足不出户而知天下事。人们已然走向了一个信息化的时代,手机、电脑、电视等多种多样的数码产品充斥着我们的生活,犹如蜘蛛结网,每一个人都处在信息时代这张巨大的网络中央,“蛛网”之内每一个细微的震颤都能了解的一清二楚。
科技的进步正给人们的生活带来越来越多的便利,马化腾亲临万达广场并成功刷脸完成支付;Nova 4手机4800万超高像素;遍布城市各个角落的高清摄像头时刻为我们的安全保驾护航。图像的变得清晰固然是好事,但在像素提高的同时却给数据的处理带来了麻烦,高清高像素也就意味着数据的维度变得更高,而高维度的数据在一定程度上也包含了许多冗余信息,如若不采取合适的方法降维,直接将高维数据作为实验数据的话,很容易会引起维数灾难,从而使得结果的准确性得不到保证,并且数据维度的提高意味着会占用更多的存储空间以及更长的计算时间,使得数据处理的效率降低。
在当下这个大数据的时代,对大数据的分析和处理是各行各业都需要的。然而大数据所具有的几大特点令其处理变得十分困难:首当其冲的数据的海量性,在我们身边各种各样的事情的发生都伴随着新的数据的出现,数据的规模不断地在扩大;然后是数据的多样性,不仅限于随处可见的文字与数字,每一张图片,每一条语音都是数据的表达方式;最后是数据的高速性,人们在日常的活动中,数据以极快的频率在不断地被创建与处理。面对数量如此庞大,种类复杂繁多的数据,想要依靠人类手工来对其进行逐一处理显然是不现实的,因此以计算机来代替人类处理数据在近年来开始迅猛发展。
机器学习是处理数据常用的方法之一,是一个由包括统计学,概率论与数理统计等多种类型的学科共同组成的交叉学科。它的核心就是让机器能够代替人,自主地对数据进行整合与处理,并寻找数据之间联系与特点,最终以此来做出预测,具体流程如图1.1所示。然而机器学习仅能在浅层的学习框架中取得良好的学习效果,当模型框架变得复杂之后机器学习就暴露出了其局限性。为了使机器学习的深度更深范围更广,深度学习理论应运而生。

图1.1 机器学习的信息流
深度学习能够模拟人的思考来对数据的特征进行自主学习。所谓的深度实际是同浅层的学习做比较而言的,浅层学习的模型结构并没有过于复杂,通常仅包含一到两层的结构,而深度学习框架可以具有更多的隐藏层,也就意味着可以组成更复杂的算法,抽象后的特征也更精确有效。随着人们对深度学习与非监督特征学习研究的深入,将两者相结合来进一步提高数据处理效果成为了目前机器学习,人工智能等诸多领域内的专家教授研讨的热点。
从近几年看,利用自动编码器来进行机器学习受到了普遍欢迎。因为同其他经典的机器学习算法对比,运用自动编码器的方法能够更好地提取到数据的抽象表达,通过训练自动编码器来进行数据降维的方法表现出了很高的性能以及稳定性。
首先从两个网络中的随机权重开始,通过最小化原始数据与其重建之间的差异,可以将它们训练在一起。所需的梯度可以很容易地通过使用链式规则,先通过解码器网络,然后再通过编码器网络反向传播回来。整个系统被称为自动编码器。在具有多个隐藏层的非线性自动编码器中,很难优化权重。对于较大的初始权重,自动编码器通常会发现较差的局部最小值;对于较小的初始权重,初期层中的梯度很小,因此无法用许多隐藏层训练自动编码器。如果初始权重接近一个好的解,梯度下降会很好地工作,但是找到这样的初始权重需要一种完全不同的算法,一次学习一层特征。
1.2 国内外研究现状
1.2.1 非监督特征学习研究现状
人类对于神经网络的研究早在上个世纪就已经开始。20世纪80年代,Hopfield首先把能量函数加入到了神经网络之中 [1]。在同一时期,BP算法(反向传播算法)[2]的提出使得对于处理多层神经网络的问题又多了一条有效的途径,也因此让神经网络再次被研究者所重视。然而在实际运用中,BP算法存在着其局限性,即只有在浅层的神经网络中才能取得较好效果,对于更深层次的神经网络无法达到预期的效果。究其原因是BP算法中的误差是反向传播的,这会导致越是处于上层的参数它所受到误差的影响就会越低,即所谓的梯度弥散问题。2006年,通过Hinton等人[3]提出的基于深度信念网络的非监督学习算法,使得深度学习神经网络中优化困难的问题得以解决,人们才重新开始重视深度神经网络的研究。自此,非监督特征学习受到了越来越多的机器学习,人工智能等诸多领域的专家教授的普遍研讨。
机器学习能够被划分为两类:监督学习和非监督学习,两者的区别在于前者所训练的样本是具有标签的而后者所训练的样本是不具有标签的。在我们的日常生活中,大部分的样本数据是没有具体的类别标签的,所以非监督学习比监督学习的使用范围更广。常用的非监督学习方法主要包括等距映射法[21]、主成分分析法[22]、局部线性嵌入法[23]等。
深度学习框架实际上是由多层的神经网络组合而成,所以特征需要被逐层的提取并去除那些不重要的信息。因此,如果要使用非监督的学习方法进行深度学习的话必须具备以下条件:
具有递归性;
主要特征可以从高维降至低维即降维后不会影响数据实验结果;
算法的内容不能够太繁杂,否则会导致深度学习框架的计算量太大。
虽然说使用上文所提到的各类线性或者非线性的数据降维算法进行深度学习同样有效果的,但是都过于复杂,拥有过于明确的目的性会导致降维后的低维数据中只有最主要的信息缺少次要信息,但是正是这些被忽略的部分往往在其他的层次上是被用来辨别数据的关键信息。因此,目前在进行深度学习的过程中,往往都是使用更加简洁易懂的算法和显而易见的评判准则。
目前,应用在深度学习中的非监督学习方法以两种最为常用:一种是确定型的自动编码器算法以及为了应对各个领域特殊的需求而改良后的算法,该种类型的算法核心是从降维后的数据中能够最大限度的还原原始数据;另一种是概率性的限制玻尔兹曼机以及相应的为了应对各个领域特殊的需求而改良后的算法,该种类型算法的核心是在限制玻尔兹曼机到达平衡状态时尽可能呈现出的是原始的数据。
1.2.2 自动编码器研究现状
自从高维度的数据开始给各类的研究和学习制造麻烦,人们就开始着手研究如何对数据进行降维。自动编码器,作为在数据降维中有着杰出效果的一种降维方法,最早起源于Rumelhard等人[2] 的研究。后来又由Bourlard等人[4]对自动编码器作了具体的说明。随着科技的进步,普通的自动编码器已经不足以有效进行现行的研究,人们发现将噪声加入到输入中能够让训练后的神经网络具有较强的稳定性,2008年,Vincent等人[5]将其改良构造出降噪自动编码器;若将稀疏性限制增加到自动编码器中即可得到稀疏自动编码器[6];为了让小范围的干扰不会对降维之后的特征产生较大影响,Rifai等人[7]构造出收缩自动编码器;Jonathan等人[8]又考虑将卷积的相关内容融入到自动编码器中,构造出卷积自动编码器。在近几年里自动编码器的发展与改进进展非常迅速,如表1.1所示,我们可以发现,由早期的理论研究渐渐发展为针对各个研究领域的特定自动编码器,并都取得了较好的效果。
表1.1 自动编码器的发展历程
自编码器名称 | 提出年份 |
传统自编码器 | 1986 |
降噪自编码器 | 2008 |
稀疏自编码器 | 2011 |
收缩自编码器 | 2011 |
卷积自编码器 | 2011 |
变换自编码器 | 2011 |
领域适应性边缘降噪自编码器 | 2012 |
-稀疏自编码器 | 2013 |
饱和自编码器 | 2013 |
非线性表示边缘降噪自编码器 | 2014 |
高阶收缩自编码器 | 2014 |
变分自编码器 | 2014 |
协同局部自编码器 | 2014 |
张量自编码器 | 2014 |
条件变分自编码器 | 2015 |
变分公平自编码器 | 2015 |
区分自编码器 | 2015 |
局部约束稀疏自编码器 | 2015 |
协同稳定非局部自编码器 | 2016 |
损失变分自编码器 | 2016 |
大边缘自编码器 | 2017 |
信息最大化变分自编码器 | 2017 |
最小二乘变分自编码器 | 2017 |
循环通道变分自编码器 | 2017 |
多阶段变分自编码器 | 2017 |
考虑到自动编码器内部的层数不能太深,所以经常对单个的自动编码器单独训练,再将其堆叠起来以便进行更深层次的学习与训练。自动编码器具有可多层堆叠、重建过程简单以及以神经学科作为支撑等优点,在人脸识别、图像分类、数据生成等方面都有着成功的应用。
虽然在深度学习框架中,自动编码器的确有着非常实用性能,并且跟其他的深度学习框架中的算法比起来,并没有那么复杂,模型更为简洁方便,但是关于自动编码器还存在着许多尚未被解决的问题例如:选择哪种途径对于数据进行预处理[9]、如何应对在实验过程中发生的过拟合问题[10]、合理的参数设置[11]以及采用什么样的算法进行优化[12]等等。所以说关于自动编码器的探索,人们还需要进行更加细致入微的研究来使得最后的分类效果达到最优。
1.2.3 数据降维研究现状
在上个世纪之前,人们在各个方面接触到的数据维度一般都在50维以下,随着互联网的飞速发展,各个领域内所需要用到的数据的维度大幅增加,“大数据”这个词汇逐渐出现在了人们的视线中,而 “维数灾难”问题也随之一起产生。在一个高维数据里往往包含了更多的便于识别与检测的信息,但同时也有许多冗余信息,不仅会降低最终分类的精确度同时还会使得计算量大大增加。因此,数据降维[13]已成为当下电子信息化时代中各领域研究的不可或缺的一步。
近几十年来人们一直没有停止对于特征选择的研究。由Togerson等人[14]首先开始进行探索并提出了多维尺度分析法。90年代起,我国的诸多专家开始普遍进行特征选择方面的探索且得到了较大收获。陈彬等人[15]证实关于特征集合的选择问题是可以找到一个多项式的算法来处理的并成功地找出了一个对应的多项式算法;朱明等人[16]找了一个选择算法,能够将启发信息进行运用使得搜索的速度增快,最终得到最优的特征集合;李宜展等人[17]将特征选择运用在了校验图形的差异方面;李青等人[18]对使用SUV(支持向量机)来进行特征选择的方法做了概括性的论述;权文等人[19]对关于特征选择方法的问题进行了全面的概括并做了更深入的论述。
数据降维的本质就是通过一些线性或者非线性的转化将数据的维度从较高压缩到相对较低。降维方法可以分为线性与非线性两大类:线性降维法常用有PCA,LDA等方法;非线性降维法常用有ISOMAP,LLE等方法(上述四种方法将在第三章中做具体的介绍)。目前常用的降维算法-PCA算法能使投影到低维度数据时方差的值最大。但PCA仅是非监督,非监督就会使得原本数据带有的分类标签不能被很好地利用。于是Fisher提出了有监督的LDA算法,但同样具有小样本问题[20]的缺点。上述两种非线性的降维方法也有着不收敛等问题,即数据的数量即使仅是微量的变化也会使得最终结果产生较大的差异,也就是所谓的鲁棒性较弱。
1.3 本文研究主要内容
本文主要介绍了基于稀疏自动编码器的非监督特征学习算法。首先通过训练集来训练一个稀疏自动编码器,然后利用训练后的稀疏自动编码器对测试集进行数据降维,得到原始数据集的稀疏表达向量,再将所提取出来的深度特征接入分类器,得到识别的准确率并与经典数据降维算法对比来评价其降维效果。
第2章 经典降维算法
若一组数据的维度较高,人们在分析与处理时就会遇到各种各样的困难。因此,降维是处理数据之前重要的也是必要的一步。本章介绍了维数灾难的定义和其对结果精度的影响,总结了一些经典的数据降维算法并进行比较。
2.1 维数灾难
1961年,Richard E.Bellman在思考动态优化问题时提出了“维数灾难”这一名词术语,它是指维数增加所造成的在处理数据时引起的诸多困难,主要包括以下三个方面的问题:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: