多标签数据特征选择的降维方法研究毕业论文
2020-02-19 09:57:04
摘 要
随着大数据的崛起,数据的结构更加复杂,数量更加庞大。数据所包含的信息越来越多,但是有用的信息却需要我们去深度挖掘。与以往不同,在多标签数据中一个实例可以对应与多个标签,这导致此前适用于标准监督学习的算法及其评估标准将不适用于多标签数据。
在多标签数据的采集过程中,数据会因为某些人为原因出现缺失的情况,让多标签学习问题变为了一个弱监督问题。为了完备缺损的标签,Glocal方法利用标签空间的低秩性,对真实标签矩阵进行低秩矩阵分解。只要找到分解后得到的两个子矩阵,便可以得到真实标签矩阵的重构矩阵。
在多标签学习模型中,利用标签间关联性是必不可少的。但是,之前经典的多标签学习算法要么仅仅利用了全局的标签关联性,要么仅仅利用了局部的标签关联性。Glocal方法将二者结合起来,通过流形正则化的方法一同运用到模型中来优化模型性能。
综上所述,Glocal方法所用的模型利用低秩矩阵分解对标签空间进行降维,并找到特征空间到降维得到的潜在标签空间的映射,最后利用流形正则化找到全局与局部标签关联性,对模型进行约束,防止过拟合。
在mulan数据集上的实验结果将对比本文所推荐的Glocal方法与经典多标签学习算法ML-KNN、ML-LOC算法的实验效果。
关键词:多标签数据;数据缺失;低秩矩阵分解;流形正则化
Abstract
With the rise of big data, the structure of data is more complex and the quantity is larger. The data contains more and more information, but the useful information needs us to mine deeply. Unlike in the past, an instance can correspond to multiple labels in multi-label data, which leads to the algorithm and its evaluation criteria previously applicable to standard supervised learning will not be applicable to multi-label data.
In the process of collecting multi-label data, the data will be missing because of some human reasons, which makes the multi-label learning problem become a weak supervision problem. In order to complete the missing label, Glocal method makes use of the low rank property of label space to decompose the real label matrix into low rank matrix. As long as the two submatrices after decomposition are found, the reconstruction matrix of the real label matrix can be obtained.
In a multi-label learning model, the use of label correlation is essential. However, the previous classical multi-label learning algorithm either takes advantage of the global label correlation or only uses the local label correlation . The Glocal method combines both to optimize the performance of the model with the method of manifold regularization.
In summary, the model in Glocal method uses low rank matrix decomposition to reduce the dimension of label space, and finds the mapping from feature space to potential label space obtained by dimension reduction. Finally, the global and local label correlation is found by manifolds regularization in order to constrain the model and prevent overfitting.
The experimental results on mulan dataset will compare the experimental results of the Glocal method recommended in this paper with the classical multi-label learning algorithm ML-KNN,ML-LOC algorithm.
Key Words:Multi-label data; missing data;low rank Matrix decomposition; Manifold regularization
目 录
第1章 绪论 1
1.1 论文研究背景与意义 1
1.2 国内外研究现状 1
1.2.1 多标签关联性研究 1
1.2.2 多标签其它相关研究 2
1.3 本文的研究内容与结构安排 2
第2章 多标签模型理论知识 4
2.1 多标签模型基础知识 4
2.1.1 多标签模型的基本框架 4
2.1.2 多标签模型评估方法 4
2.1.3多标签模型类型评估方法 6
2.2 非负矩阵分解 6
2.3 流形正则化方法 8
第3章 多标签学习经典算法 10
3.1 ML-KNN算法 10
3.2 ML-LOC算法 11
3.2.1 ML-LOC算法思想 11
3.2.2 ML-LOC模型构建 12
3.3 SSWL算法 13
3.3.1 SSWL算法思想 13
3.3.2 SSWL模型构建 13
3.4 MAXIDE算法 14
第4章 Glocal算法介绍 15
4.1 Glocal算法三个损失函数介绍 15
4.1.1 标签矩阵的重构损失 15
4.1.2 潜在标签空间及其预测值之间的平方误差 15
4.1.3 全局和局部流形正则化损失 16
4.2 Glocal模型构建 16
4.3 Glocal模型求解 17
第5章 实验结果与分析 20
5.1 实验数据集 20
5.2 实验参数设置 20
5.3 实验结果 20
5.3.1 数据恢复情况 20
5.3.2 算法性能比较 21
5.4 实验结果分析 23
第6章 总结与展望 24
6.1 主要研究成果 24
6.2 不足与展望 24
参考文献 25
致 谢 27
第1章 绪论
1.1 论文研究背景与意义
随着大数据研究的深入,我们对于数据的认知也越来越深刻,数据结构越来越复杂,数据所包含的意义也越来越多元。多标签数据便是在传统的单标签数据发展而来的,不同于传统的单标签数据中一个实例对应一个标签,在多标签数据中一个实例对应多个标签。
多标签数据在现实生活中普遍存在。在文本分类中,一个新闻报道中可能包含苹果、手机、乔布斯等多个主题;在一段音频中可能包含奥运会、北京、田径等多个内容;在一张图片中可能包含天空,海,泰坦尼克号等多个标签;而在一段基因中可能包含多个功能。
多标签数据在多个领域也得到广泛关注与应用。多标签数据在文本学习、图像标注、多媒体内容标注、信息检索、生物信息学、网络挖掘等多个领域中都有其具体应用。
但是,由于多标签的多语义属性,传统的单标签监督学习算法在多标签数据的应用上却显得无能为力。为了解决有关于多标签数据的问题,对多标签的学习显得尤为重要。
1.2 国内外研究现状
随着大数据的到来,每天产生的海量数据越来越多,数据的结构也不同于以往越来越复杂,海量复杂数据的快速处理需要进一步研究才能有效挖掘出里面所包含的信息,多标签学习便是因此应运而生的。
1.2.1 多标签关联性研究
多标签学习不同于以往的单标签学习,实例所对应的标签数量是多个,这使得传统经典单标签算法需要加以改进才能有效处理多标签数据。为了能够对多标签学习有一个初步的认知,Zhou等人[1]对多标签学习的各个方面进行了简单总结,包括模型的公式表达、一般建立方法、评估标准以及系统复杂程度等。
通常,对于多标签的研究自然而然地倾向于研究标签间的关联性,这是由于标签个数的增长,导致了标签空间指数幂增长。为了有效利用标签之间的相关性,各种各样的理论被提了出来。通过标签间关联性的阶数,多标签理论学习大致可以分为三类,第一阶完全忽略标签间关联性,直接构建多个独立的单标签分类模型,经典的算法有BR算法[17](Binary Relevance)。其中,BR算法由于其模型构建简单而深受喜爱,有的人经常愿意拿自己的算法与它进行实验比较,而有些人则愿意去改良BR算法来更好地解决多标签问题[11];第二阶采用成对的标签关联性,经典的算法有CLR算法[25](calibrated label ranking);高阶采用全部或者随机标签子集间关联性构建模型,经典的算法有CC算法[26](classifier chain)。
许多多标签算法普遍接受全局的标签关联性,但是,在某些领域中考虑局部的标签关联性是十分必要的。对此,Nan等人[12]通过求取在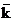 邻域中排序在前M个的k正负标签子集来利用标签的局部关联性。Huang和Zhou[7]提出了ML-LOC算法来得到标签之间的局部联系。而Zhu等人[2]提出了Glocal算法希望同时考虑全局与局部标签之间的相互关联性。
邻域中排序在前M个的k正负标签子集来利用标签的局部关联性。Huang和Zhou[7]提出了ML-LOC算法来得到标签之间的局部联系。而Zhu等人[2]提出了Glocal算法希望同时考虑全局与局部标签之间的相互关联性。
1.2.2 多标签其它相关研究
除了研究标签间关联性,研究实例空间也很重要,Lin等人[13]研究多标签特征选择方面的知识。而找到实例空间与标签空间的关系有利于更好地了解二者之间的内部联系,Zhang等人[15]利用标签间关联性学习额外的标签-特殊特征来提高模型准确率。
在数据流中,标签个数不是固定的,可能会涌现出新的标签。为了解决这个问题,Zhu等人[3]提出了一个MuENL方法,不仅仅预测现有标签,还对新涌现的标签建立探测器与分类器。
基于人为采集的缘故,多标签数据会因为人的兴趣爱好和有限知识而常常并不是完整的。这一类问题为弱标签问题,Sun等人[9]提出了一种WELL方法解决。Ma等人[16]利用标签空间的低维特性解决弱标签问题。而Xu等人[18]利用矩阵边信息对缺损多标签矩阵进行完备化来解决。其中,关键部分的理论证明来源于Candès等人[19]提供的矩阵完备化证明,该方法还有许多运用的地方[20]。
在多标签模型实验对比过程中,多种模型评估标准被提出来。但是。各个评估标准对于多标签模型的评估并非是一致的,即不能仅仅通过一个评估标准就轻易判断多标签模型的优劣,为此,Wu等人[5]提出了一种多标签评估标准的联合视图来处理该问题。
在对多标签学习的进一步研究过程中,如果将一个实例推广到多个实例,则产生了多实例多标签(MIML)问题。相较于多标签问题,MIML问题更加复杂,更加难以解决。Huang等人[10]提出了MIMLFAST方法来快速有效解决MIML问题。而对于现在正流行的深度学习,Feng等人[4]提出了深度MIML 网络来结合深度学习与MIML问题。
1.3 本文的研究内容与结构安排
本文的研究内容主要介绍Glocal算法。Glocal算法主要有两个创新点,一是利用低秩矩阵分解找到缺失的标签矩阵,二是通过全局与局部流形正则化将标签的全局与局部关联性相结合。本文将通过在mulan多标签数据上Glocal与ML-KNN、ML-LOC算法的实验结果相对比,找到各个算法的优缺点。并希望Glocal方法能够利用低秩矩阵分解中的非负矩阵分解以及半监督的学习方法来优化模型。
本论文一共包括六个章节,安排如下:
第一章是绪论,包括了论文研究背景与意义、国内外研究现状、论文的研究内容与结构安排三个方面。
第二章是多标签模型理论基础,主要包括了三个方面。第一个包括了多标签模型基本模型框架、多标签模型评估方法、多标签模型类型评估方法三个多标签基础知识;第二个包括非负矩阵分解,了解其原理有利于理解低秩矩阵分解,并对Glocal模型优化提供帮助;第三个包括流形正则化,了解其原理有利于理解Glocal模型中全局与局部标签关联性的构造。
第三章是多标签学习经典算法,主要包括经典的多标签学习算法ML-KNN、ML-LOC、SSML以及多标签矩阵完备算法MAXIDE。ML-KNN、ML-LOC算法将在实验中利用MAXIDE算法对缺失标签完备化,并与Glocal方法作对比。SSML算法提供了半监督的思想,对优化Glocal方法提供了指导作用。
第四章是论文模型构建,包括了三个损失函数,分别是真实标签矩阵的重构损失、潜在标签空间及其预测值之间的平方损失、全局和局部流形正则化损失。通过这三个损失函数,Glocal方法构建多标签模型,并通过交替梯度下降法对模型求解,最后会贴出伪代码。
第五章是实验结果与分析,Glocal算法将在mulan多标签数据集上进行实验,并与传统多标签算法ML-KNN、ML-LOC做对比,所得的实验结果将显示各个算法性能的好坏。
第六章是总结与展望,包括了论文主要研究成果、不足和展望两个方面。对Glocal方法进行总结与分析,并提出了未来有待改进、深入研究的地方。
第2章 多标签模型理论知识
本章将介绍多标签模型的三个基础知识与两个理论知识。
在三个多标签基础知识中,了解多标签模型的基础框架,有利于读懂这篇论文;理解多标签模型评估方法,有利于有效了解多个评价多标签模型好坏的评估标准;通过多标签模型类型评估方法,有利于了解模型的类型及复杂程度。
而在两个理论知识中,非负矩阵分解[24]是低秩矩阵分解方法之一,利用非负的约束条件可能对Glocal方法进行优化。NMF基于某些领域中数据的非负性对非负低秩矩阵进行快速的分解,其速度远远高于传统的矩阵分解算法,例如主成分分析等,对于大规模数据,它也有良好的表现。
流形正则化[23]则是Global方法联合全局和局部关联性的关键。MR将数据几何分布的特点作为知识约束模型,在对有监督与无监督数据同时进行学习的过程中,发现其在无监督数据对有监督数据有效的指导效果。
2.1 多标签模型基础知识
2.1.1 多标签模型的基本框架
通常规定,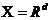 表示d维特征空间,
表示d维特征空间,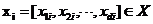 表示第i个实例,
表示第i个实例,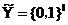 表示l维真实标签空间,
表示l维真实标签空间,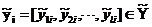 表示第i个实例对应的真实标签。当出现缺失标签的情况时,我们假定
表示第i个实例对应的真实标签。当出现缺失标签的情况时,我们假定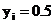 ,则我们定义给定的含缺失标签的标签空间为
,则我们定义给定的含缺失标签的标签空间为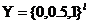 。
。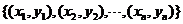 表示由n个实例组成的训练集。
表示由n个实例组成的训练集。
多标签模型想要学习一个从特征空间到真实标签空间的映射函数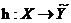 ,另一个公认替代
,另一个公认替代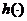 的函数为一个实值函数
的函数为一个实值函数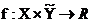 。此时,
。此时,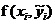 能被视作
能被视作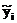 作为
作为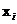 合适标签的预测置信度值,我们期望对于每个实例而言相关标签的预测置信度值应该比不相关标签的值大。通过一个阈值函数
合适标签的预测置信度值,我们期望对于每个实例而言相关标签的预测置信度值应该比不相关标签的值大。通过一个阈值函数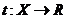 ,可以通过
,可以通过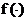 得到:
得到: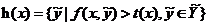 。
。
对这个映射函数,我们将在模型中构建一个真实标签与预测标签的损失函数,为了约束这个函数,防止其过拟合,我们将利用多标签的各种特性对模型进行正则化。了解多标签模型的基础框架将有利于对多标签问题求解有一个初步的了解。
2.1.2 多标签模型评估方法



