基于统计学习方法的北京市PM2.5的影响因素研究毕业论文
2020-04-24 11:18:10
摘 要
随着近年来我国工业化程度不断加深,带来了严重污染问题,人们越来越关心空气质量。PM2.5是评估空气质量的重要指数,但分析以往的空气质量数据,PM2.5浓度有明显的非线性和不确定性波动,很难用传统的时序模型进行预测。本文采用LSTM循环神经网络模型,基于Keras库,以2010年PM2.5数据为基础,预测2011年至2014年PM2.5浓度,并和实际结果进行比较。实验结果表明,LSTM模型在PM2.5预测方面有着较好的表现。
关键词:空气质量 LSTM 神经网络 Keras
Study on Influencing Factors of PM2.5 in Beijing Based on Statistical Learning
Abstract
With the deepening of industrialization in China in recent years, serious pollution problems have arisen, and people are increasingly concerned about air quality. PM2.5 is an important index for assessing air quality. Thinking of the analysis of past air quality data, PM2.5 concentration has obvious nonlinear and uncertainty fluctuations, it is difficult to predict with traditional time series models. In this paper, the LSTM cyclic neural network model is used. Based on the Keras library, we will predicet PM2.5 from 2011 to 2014 and compare with the actual results. The experimental results show that the LSTM model has a good performance in PM2.5 prediction.
Keywords: air quality , LSTM ,neural network ,Keras
目录
摘要 2
Abstract 3
第一章 引言 5
1.1研究背景 5
1.2国外研究回顾 5
1.3国内研究回顾 7
1.4本文主要工作 7
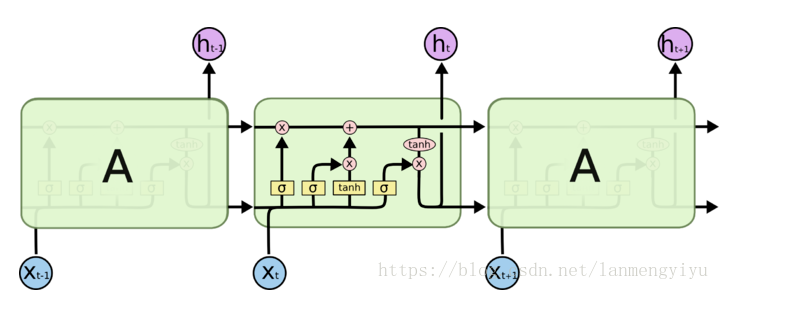
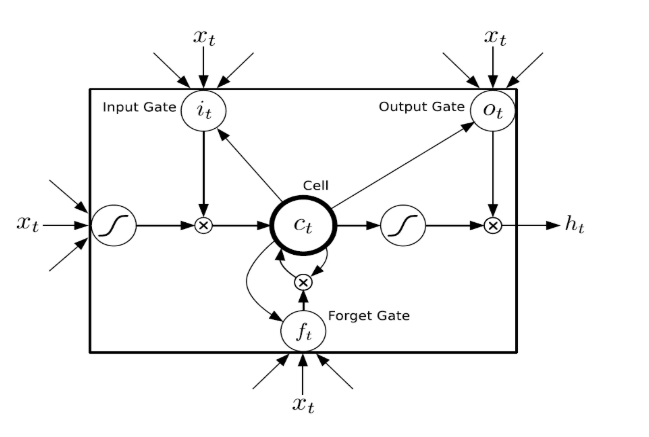
第二章 LSTM模型概述 9
2.1 RNN(循环神经网络) 9
2.2 LSTM网络 10
第三章 基于LSTM的PM2.5预测模型 13
3.1 Keras简介 13
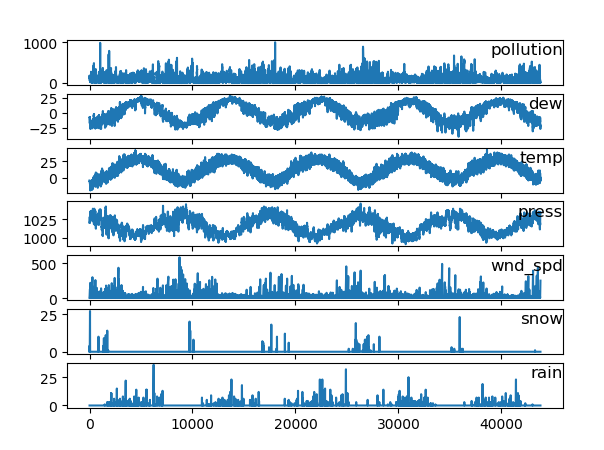
3.2数据处理 13
3.3构造模型 15
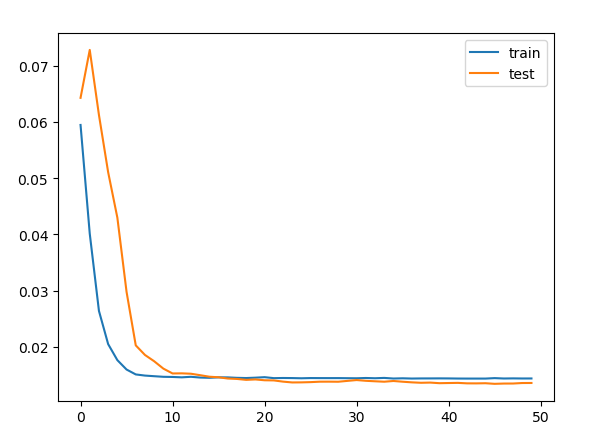
3.4实验结果及分析 15
第四章 模型评价 17
第五章 结语 19
参考文献 20
致谢 21
附录 22
第一章 引言
1.1研究背景
工业的快速发展导致发展中国家间歇性的爆发PM2.5或雾霾,这带来了巨大的环境问题,特别是北京等大城市,伴随着大量的人口,消费和污染,间歇性爆发的空气污染严重影响了每个公民的生活:生理疾病,抑郁症和交通能见度差,空气质量问题日益成为人们关注的焦点之一。PM2.5作为空气污染的重要组成部分,对PM2.5影响因素的研究有着重要意义。PM2.5又称细颗粒物。细颗粒物指环境空气中空气动力学当量直径小于等于 2.5 微米的颗粒物。它能较长时间悬浮于空气中,其在空气中含量浓度越高,就代表空气污染越严重。与较粗的大气颗粒物相比,PM2.5粒径小,含有大量的有毒有害物质,且寿命长、输送距远,因而对人体健康和大气环境质量的影响更大,对空气质量和能见度的影响比PM10更直观。
1.2国外研究回顾
Tao Zou,Shuo Li,Shuyi Zhang,Hui Huang[3]等8名作者认为PM2.5与混杂因素之间的关系仍不清楚。这种关系的量化需要有效的时间跨度数据和全面的统计分析,以便测量不确定性并调整混杂因素。统计模型如贝叶斯层次时空模型和广义加法模型被用于研究美国的环境空气污染。为了评价人类健康对PM2.5的影响,他们考虑了准实验(QES)方法,并且建议的调整可与QES一起用于评估排放对PM2.5浓度的影响。截至2014年2月,北京市的2.5污染水平没有超过2012年的水平,空气质量实际上恶化了。尽管APEC采取了大量措施,基本上关闭了NCP经济的一个重要部分10天,但2014年11月6日至12日期间的平均PM2.5为52.2μgm−3,比35μgm−3的健康阈值还高。这表明,在现有的核电站能源消耗效益下,北京的不太可能在很长一段时间内达到35μgm−3的清洁空气。因此,为了使北京达到健康空气的标准,必须向低排放工业装置的替代形式过渡。由于PM2.5浓度受气象条件的影响较大,我们提出了一种统计方法来调整PM2.5浓度与气象条件的关系,可用于监测某一地区的PM2.5污染。中国国务院制定减少污染目标后,采用调整后的月平均值和百分位数来检验北京PM2.5水平是否有所降低。测试结果显示,与2012年相比,2013年和2014年PM2.5浓度明显增加,而不是减少。我们对2014年11月亚洲太平洋经济合作会议和年度冬季供暖两个准实验进行了分析,以了解排放对PM2.5的影响。分析得出结论,北京及其周边华北平原地区从以煤炭为主的能源消费向更加绿色的替代能源的根本转变是解决北京PM2.5问题的关键。
Zhou Q, Jiang H, Wang J 首次提出了一种基于数据预处理和分析的混合EEMD- GRNN ( 集合经验模态分解一通用回归神经网络)模型,用于提前一天预测PM2.5浓度[14]。Sahu S K, Mardia K V [15]使用贝叶斯kriged卡尔曼滤波模型对PM2,5时空过程进行短期预测,利用Kriging方法建立模型的空间预测并使用马尔可夫链蒙特卡罗技术实现,在时间和空间上获得良好的预测效果。Kurt A, Oktay A B [8]提出了一种基于地理的模型,使用MLP提前三天预测SO2,CO和PM10的日平均浓度,其采用了3种地理模型:单站点邻域模型,双站点邻域模型和基于距离的模型。结论显示,基于地理的模型优于普通模型,尤其是基于距离的模型。如果在地理模型中增加更多的气象变量,预计仍有很大的改进空间。
XiaopingYang,ZhongxiaZhang, ZhongqiuZhang, LirenSun, CuiXu, andLiYu提出了一种基于时间序列分析的北京市空气质量指数预测模型,他们收集了北京自2013年以来连续29个月的AQI数据,构建了一个动态结构预测模型[7]。采用统计方法得到预测模型的最大似然估计。并进行了短期和长期试验,验证了模型的准确性和可靠性。实验反映了这个模型的两个亮点。首先,模型对空气质量指数的突发变化非常敏感,并且在预测突发变化方面表现得非常好,包括突发事件和扩散事件。其次,模型具有很强的稳定性,不能承担长期的空气质量指令的任务。最后,由于时间粒度的限制,模型有时“预见”,但从不延迟或延迟烟雾的突发变化。
1.3国内研究回顾
王嫣然[1]利用2013年1月一2014年12月北京地区PM2s和PM1o监测数据和同期近地面气象观测数据,采用非参数相关分析( Spearman秩相关系数)法对北京地区不同季节PM2.5和PM10浓度对地面气象因素的响应进行了研究。敖希琴,郑阳,虞月芬,汪金婷,李凡.[9]提出了基于多元时间序列(ARMAX)的PM2.5预测方法。李栋,薛惠锋,张文宇,方铭[10] 提出了一个基于相关分析、自回归分布滞后模型、果蝇优化算法、核极限学习机的在线PM2.5日浓度混合预测模型。谢志萍基于北京2014年至2015年PM2.5与土地利用关系,进行了时间序列分析,并建立了土地利用类型指示指数同PM2.5浓度空间分布间的线性回归方程[2]。研究结论表明: 1、北京的月PM2.5浓度呈现波浪形变化规律,2、各监测站点PM2.5浓度降序排列为:冬季,秋季,夏季,春季。
相关图片展示: