基于博弈树搜索和强化学习的gomoku系统毕业论文
2020-02-19 07:58:00
摘 要
2016年3月,AlphaGo,一个诞生于谷歌旗下DeepMind公司的人工智能,展开了与世界围棋冠军李世石的围棋对战,最终以大比分4:1获胜。AlphaGo的出现引起了人类对人工智能的广泛关注。人工智能的一个长期目标是建立在具有挑战性的领域进行学习、从零开始直到最终获得超越人能力的算法。AlphaGo运用了深度学习,结合了监督学习和强化学习的优点,通过从人类专家的动作中进行监督学习,进而通过自我对弈强化学习掌握博弈精神。而谷歌公司后来发布的AlphaGo Zero版本在单纯利用强化学习,仅仅用了3天的自我对弈,就以100:0的绝对优势打败了AlphaGo,这样的成功预示着人工智能在未来的迅猛发展,对于其他困难领域,如医疗、生物、航天,在未来提高执行效率、减少人工错误都有着很大的意义。因此,本研究对于近几年人工智能(AI)的发展进程和算法进化进行探究,以五子棋作为研究内容,尝试在五子棋领域对经典人工智能的博弈树搜索和后来出现的深度强化学习的算法性能进行比较,从而得到算法进化的主要思路和方向,为学习深度学习和强化学习提供更好的优化思想。
主要研究工作如下:
首先,了解五子棋和围棋AlphaGo、AlphaGo Zero的基本规则、主流技术。学习了博弈树搜索和神经网络算法的相关文献,掌握了两种算法的核心思想和整体框架。进而搭建基于不同算法的两个gomoku系统。
接着,针对经典人工智能的博弈树搜索,参考了相关文献和浏览了相关技术的博客,找到了在剪枝算法基础上可进一步优化算法执行效率和速度的方法,最终在保证下棋质量的情况下减少了计算时间。
之后,对于深度强化学习所训练的模型,早期利用数量有限的人类样本实施训练,在掌握基本游戏规则之后,利用和博弈树算法对弈进行强化学习,最终得到了具备明显博弈效果的模型。
最终,从训练速度、计算次数、决策判断、对战胜率等方面对两种算法进行剖析分析,并实现和机械臂、机器视觉的互联,指导真实场景的对弈。
本次设计中的突破点在于对深度强化学习算法模型的训练,尝试在普通配置计算机上在有限时间中训练出可与人对弈的模型。
关键词:人工智能;深度学习;强化学习;博弈树;人机对弈系统。
Abstract
In March 2016, AlphaGo, a Google-owned artificial intelligence unit of DeepMind, fought against world go champion Lee Sedol and won the game by a large margin of 4:1.The appearance of AlphaGo has attracted widespread attention from human beings to artificial intelligence..A long-term goal of artificial intelligence is to build on learning in challenging areas, from scratch to the final acquisition of algorithms that transcend human capacity.AlphaGo mainly utilizes the method of deep learning, combines the advantages of supervised learning and reinforcement learning, and obtains the rules of the game from human knowledge through supervised learning from the actions of human experts. Google's later release of the AlphaGo Zero version simply uses reinforcement learning , and after just three days of self-training, it beat AlphaGo with a 100-0 absolute advantage. This success signifies the rapid development of artificial intelligence, for other difficult areas, such as medicine, biology and spaceflight, to improve the efficiency of implementation, reduce human errors in the future are of great significance.Therefore, this research explores the development process and algorithm evolution of artificial intelligence (AI) in recent years, and takes Gobang as the research carrier. This paper attempts to compare the performance of game tree search of classical artificial intelligence with that of deep reinforcement learning in the field of Gobang, so as to get the main idea and direction of the evolution of the algorithm. It provides a better optimization idea for deep learning and intensive learning.
The main research work is as follows:
First of all, understand the basic rules of Gobang and go AlphaGo,AlphaGo Zero, mainstream technology. The related documents of game tree search and neural network algorithm are studied, and the core idea and the whole frame of the two algorithms are mastered. Finally, two gomoku systems based on different principles are built.
Then, according to the game tree search of the classical artificial intelligence, referring to the relevant literature and browsing the blog of the related technology, we find the method which can further optimize the efficiency and speed of the algorithm execution on the basis of the pruning algorithm. In the end, in order to ensure the quality of action, the calculation time is reduced.
After that, for the model trained by deep reinforcement learning, a small number of human samples are used in the initial training. After mastering the basic rules of the game, the game tree algorithm is used for reinforcement learning. Finally, the model with obvious game spirit is obtained.
Finally, the two algorithms are analyzed from the aspects of training speed, calculation times, decision-making judgment, winning rate and so on, and the interconnection with mechanical arm and machine vision is realized to guide the game of real scene.
The breakthrough point of this design is to train the model of deep reinforcement learning algorithm, and try to train the model which can play game with people in the limited time on the ordinary configuration computer.
Keywords: artificial intelligence; deep learning; reinforcement learning; game tree; man-machine game system.
目录
第1章 绪论 1
1.1研究背景及意义 1
1.2国内外研究现状 2
1.2.1 国内研究现状 2
1.2.2 国外研究现状 2
1.3 本文主要研究内容 3
第2章 博弈树搜索研究 5
2.1 博弈树搜索基础 5
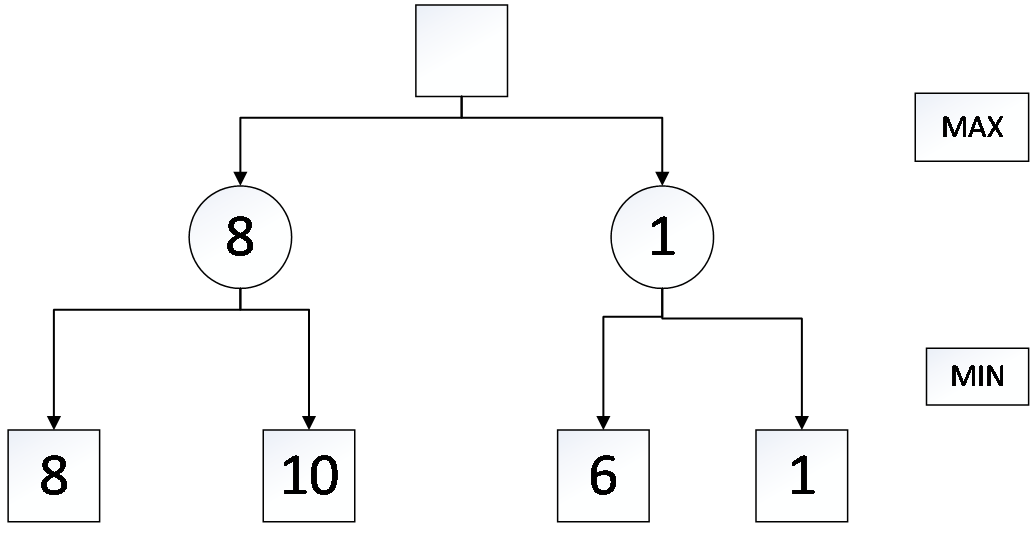
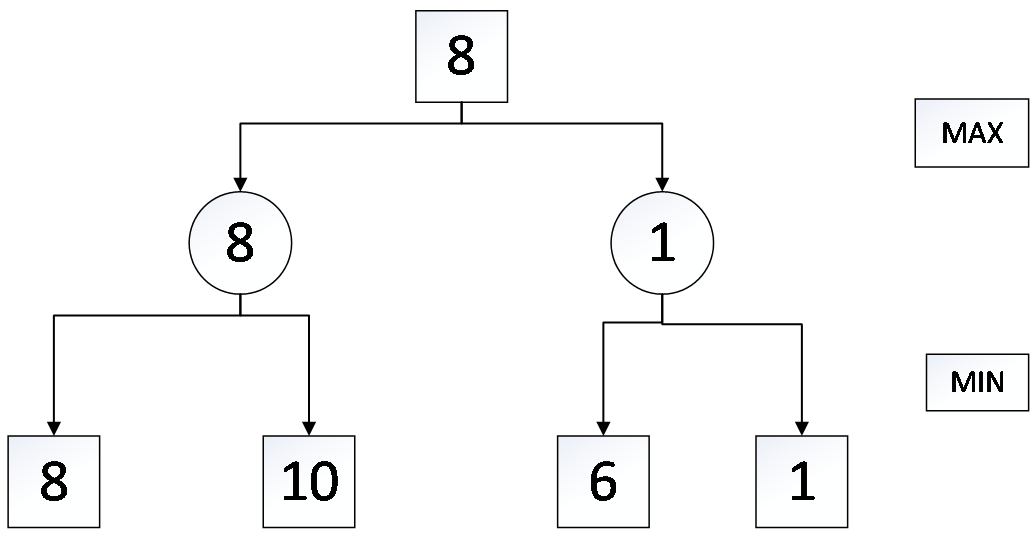
2.2 极大极小搜索 5
2.3 alpha-beta剪枝 6
2.4 本章小结 7
第3章 深度强化学习研究 8
3.1 深度学习基础 8
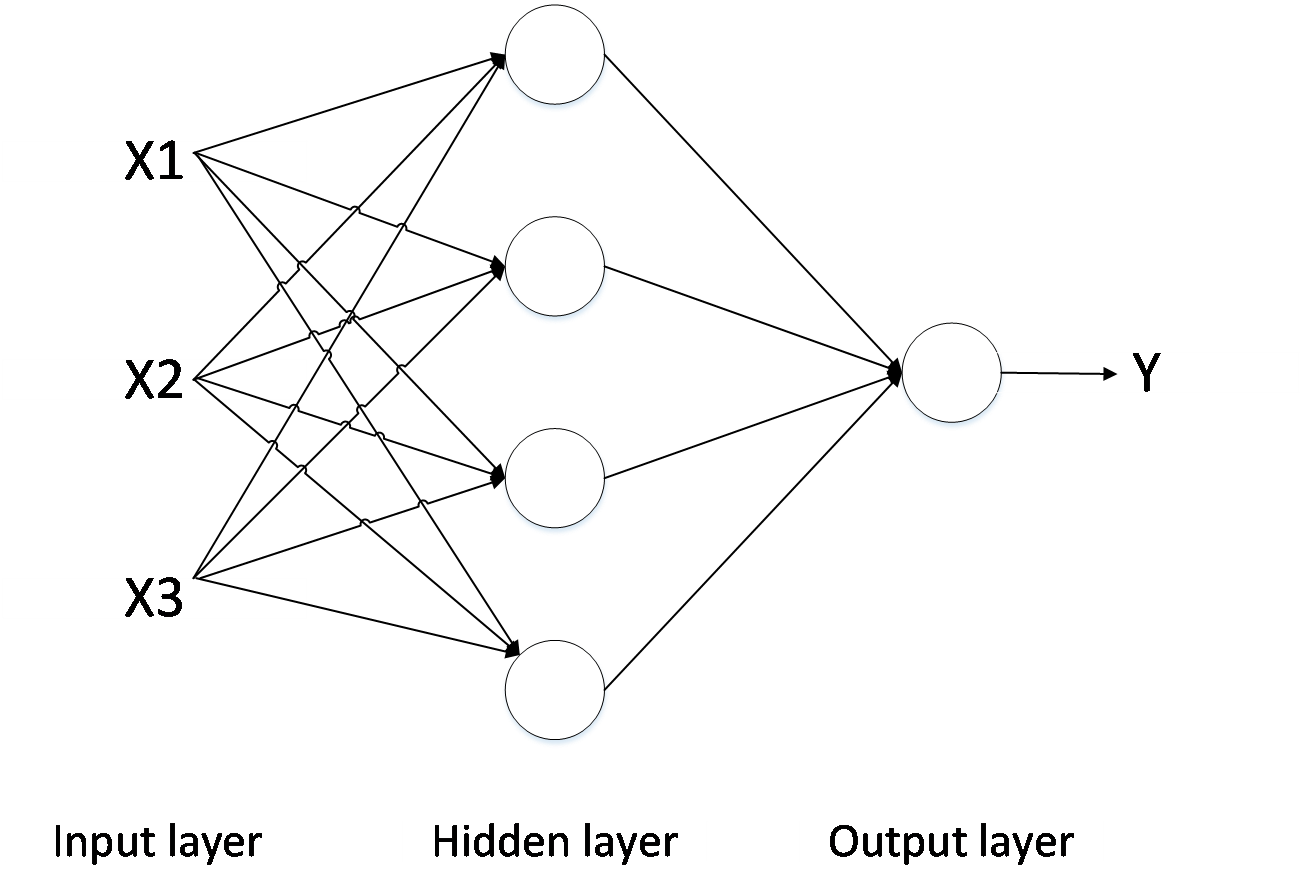
3.1.1 神经网络概述 8
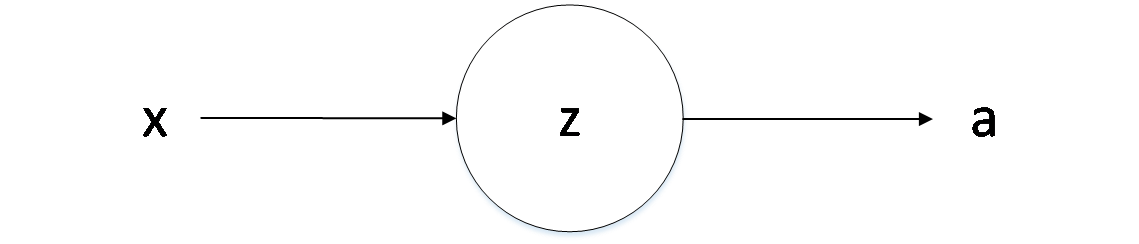
3.1.2 正向预测和反向传播分析 9
3.1.3 Adam梯度下降法 10
3.1.4 正则化和拟合问题 11
3.1.5 卷积神经网络 12
3.2 强化学习基础 13
3.2.1 马尔科夫决策过程 13
3.2.2 强化学习决策方法 14
3.2.3 蒙特卡洛模拟方法 14
3.3本章小结 16
第4章 基于博弈树搜索的gomoku系统 17
4.1 结构框架 17
4.2 搜索算法 18
4.3 评估函数 19
4.4 算法优化 20
4.5 最终表现 21
4.6 本章小结 22
第5章 基于深度强化学习的gomoku系统 23
5.1 结构框架 23
5.2 神经网络 23
5.2.1 构建网络结构 24
5.2.2 定义损失函数 26
5.2.3 选择优化器 27
5.3 模拟搜索 28
5.4 模型训练 29
5.4.1 监督学习模式 30
5.4.2 强化学习模式 30
5.4.3 训练过程 31
5.5最终表现 34
5.6本章小结 35
第6章 基于博弈树搜索和深度强化学习gomoku系统对比 36
6.1 基于博弈树搜索的gomoku系统特点 36
6.2 基于深度强化学习的gomoku系统特点 36
6.3 本章小结 37
第7章 whut智能人机对弈项目应用 38
7.1 whut智能人机对弈项目内容 38
7.2 gomoku算法在whut智能人机对弈项目的应用 39
7.3 whut智能人机对弈项目实验成果 40
参考文献 41
致谢 42
第1章 绪论
1.1研究背景及意义
人工智能一直是当下发展最具前瞻性并备受人们关注的一个话题。人工智能是计算机科学的一个分支,其目的是能够了解智能的实质,以求创造出一个可以类似人脑做出反应的智能机器人,换言之,就是希望可以使机器能够胜任一些通常需要人类智能才能完成的工作。因此人工智能在一定程度上代表了信息时代的新里程碑。然而在不同的时代下,对于人工智能的定义也有所不同,现时代的人工智能已经不仅仅局限于实现需要人类智能完成的任务,而是在具有挑战性的领域里建立进行学习、决策并且逐渐超越人类智能的机器人,这也是当下对于人工智能的一个长期目标。这个目标意味着在未来依靠人工智能不仅可以完成需要大量脑力或体力的工作,还可以在困难领域,如航空航天、地质勘探、医疗等获得人类所未触及的研究发现,这样巨大的发展为我们的生活、工作都带来了更多的可能性[1]。
棋类游戏是人类智力方面最具挑战性的领域之一,因此从人工智能诞生开始,其在棋类游戏领域的探索便一直在进行。最初的人工智能注重算法的计算能力。1997年,IBM的“深蓝”战胜了国际象棋冠军卡斯帕罗夫,“深蓝”做到了可以预判12步[2]。这样的算法依靠强大的计算能力取胜,然而并不是在所有领域中有有效,在围棋方面尽管可以训练到无限接近于人的能力,但始终无法超越,因为围棋不仅仅需要计算能力,还需要思考,因此以人类知识为基础来训练算法的思考能力,即从头开始建立一个可以思考的类似人脑的算法[3]。之后在2016年3月,谷歌公司所研发的AlphaGo打败了世界围棋冠军李世石。AlphaGo拥有模拟人类大脑的神经网络,这样的一种可学习进而优化自身算法的出现也毫无疑问的引起了广泛关注[4]。
五子棋,一种双人对弈的策略型游戏,起源于尧帝时期,其棋具早期与围棋通用,但后来演变为专属于五子棋的十五路棋盘[5],在《辞海》中记到:“五子棋是棋类游戏,两人对局,轮流下子,先将五子连成一行者为胜。”由此可见,五子棋的历史久远,因此在有AlphaGo的经验可考下,本次课题尝试将人工智能融入五子棋游戏,以五子棋作为研究内容,在充分了解五子棋规则的情况下,建立模型,检验智能化效果。
因此本课题名称为基于“博弈树搜索和强化学习的gomoku系统”,意义则是通过在五子棋领域分别建立经典人工智能算法和新兴的深度强化学习算法进行对比得出算法进化的优势和特点,从而验证算法进化的主要思路和方向,为学习深度学习和强化学习提供更好的优化思想。并将两种系统应用到智能机器人对弈项目中,检验实践效果。
1.2国内外研究现状
1.2.1 国内研究现状
在工业4.0的大背景下,从2009年开始我国针对人工智能的政策有了不断的演变过程,从物联网到大数据,再到人工智能,随着发展核心词汇的不断变化,体现了国家发展政策的不同重点,而2017年后人工智能成为了最为核心的主题。相比于国外,我国人工智能企业的研究主要集中在计算机视觉和语音识别,并且企业更加看重智能机器人、无人机和智能家居等终端产品。
在人工智能热潮之下,各行各业都在研发可应用的人工智能技术,这一市场需求直接影响着人才学习方向和就业,各专业的人才都在尝试着将人工智能融入,利用人工智能结合专业知识从而开发专属行业的应用科技。我国的华为、阿里巴巴、小米等企业对此集中了高密度的人工智能人才,企业研发团队对机器学习、深度学习算法能力的增强使得企业视觉和语音等技术得以不断突破,同时还纷纷研发出了AI计算机芯片[6]。在工业4.0的大政策推动下,中国的市场真正实现了人才和科技相互促进的现状,在国家政策的鼓励下、人才思维的突破下、企业发展的飞势下以及科技能力的进步下,人工智能还拥有着极大的发展空间,未来在生物、医疗等领域的发展不可预估,但不可忽视的是人工智能将会对中国各行业的发展都产生巨大的影响。
在回顾国内学者对于这一方面的理论研究时,笔者找到了大量从21世纪初始就开始进行五子棋对弈的相关实验和研究方法。在2015年罗文浩利用了经典AI算法实现了五子棋的人机对弈平台,算法的实现是以alpha-beta剪枝算法和搜索作为理论基础,这一方法和本次设计不谋而合。而后2016年又有郑培铭和何丽两位学者在搜索的基础上进行了优化,提出使用置换表和PVS(Principal Variation Search)算法提高搜索效率。在深度学习和神经网络发展迅猛的势态下,将神经网络结合到游戏AI的尝试也在不断地进行。2016年陈桥实现了基于BP神经网络的五子棋自学习系统,将神经网络代替经典算法中的评估函数,并通过自学习自动调整网络权值。这些研究的实现和发展表示了智能算法在逐渐进步,趋于更自主化,同时为本次设计思路提供了许多新的概念和理解。
1.2.2 国外研究现状
20世纪70年代出现了模拟人类专家的指导系统——专家系统,首次实现了人工智能从理论到实际应用的跨越。之后随着互联网技术的出现,人类对于人工智能的研究再一次进入高潮。1997年IBM的超级计算机“深蓝”打败了国际象棋世界冠军,这一成功成为了人工智能发展史上标志性事件。而从2011年至今,随着大数据、云计算、互联网、物联网等信息技术的发展,以深度神经网络为代表的人工智能技术也随之飞速发展,图像识别、无人机驾驶等智能领域都迎来爆发式增长的新高潮[7]。
2016年谷歌公司发布AlphaGo最初版本之后,深度学习和强化学习的功能再次让学者惊叹,相继出现了大量关于深度学习和强化学习相结合的实验研究。DeepMind在认识到深度学习对于逼近函数的优势和强化学习的快速性之后,开始将神经网络和Q-learning算法结合成深度Q网络,Q-learning是强化学习中决策方法的一种,通过动作和奖励逼近拟合函数,强化决策水平,而这一结合对逼近Q-learning函数产生了很好的效果。之后DeepMind又将策略学习和Q-learning相结合,提出了强化学习的A3C算法。经过对算法的不断优化和创新,DeepMind创造了AlphaGo Zero一种完全不需要人类数据参与的智能AI,并在相关论文中提出利用蒙特卡洛搜索和神经网络相结合代替评估函数的方法,从而更加提高了强化学习的可靠性,是本次设计的启发思路。
1.3 本文主要研究内容
本文将通过七章内容介绍本次设计中应用到的理论知识、系统实现过程以及系统在whut智能人机对弈项目中的应用。第一章主要介绍了本次设计的背景和需要实现的目的,同时对本次设计研究内容进行了大致的阐述。
本文第二章介绍了为实现基于博弈树搜索的五子棋系统需要的理论知识。首先论述了博弈树搜索的概念,之后介绍了在搜索基础上产生的极大极小算法和优化的alpha-beta剪枝算法,其中对在本设计中应用到的alpha-beta剪枝算法进行了详细的论述。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:
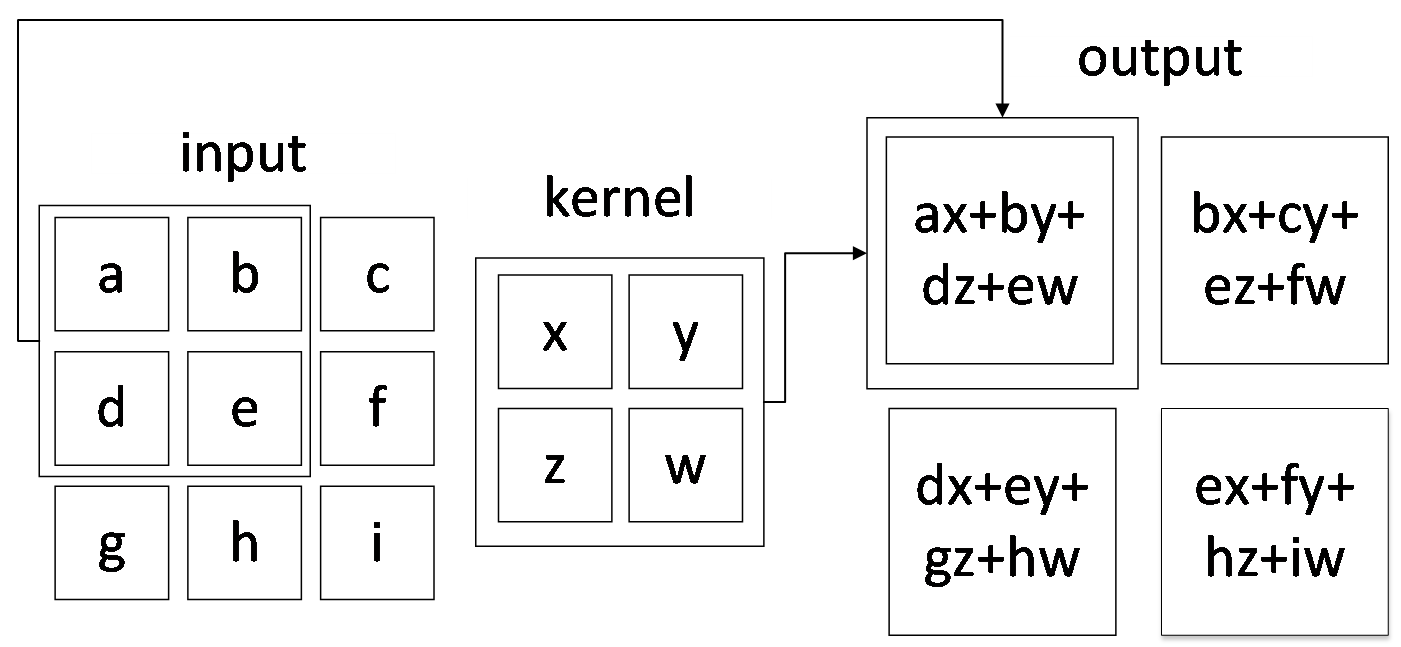
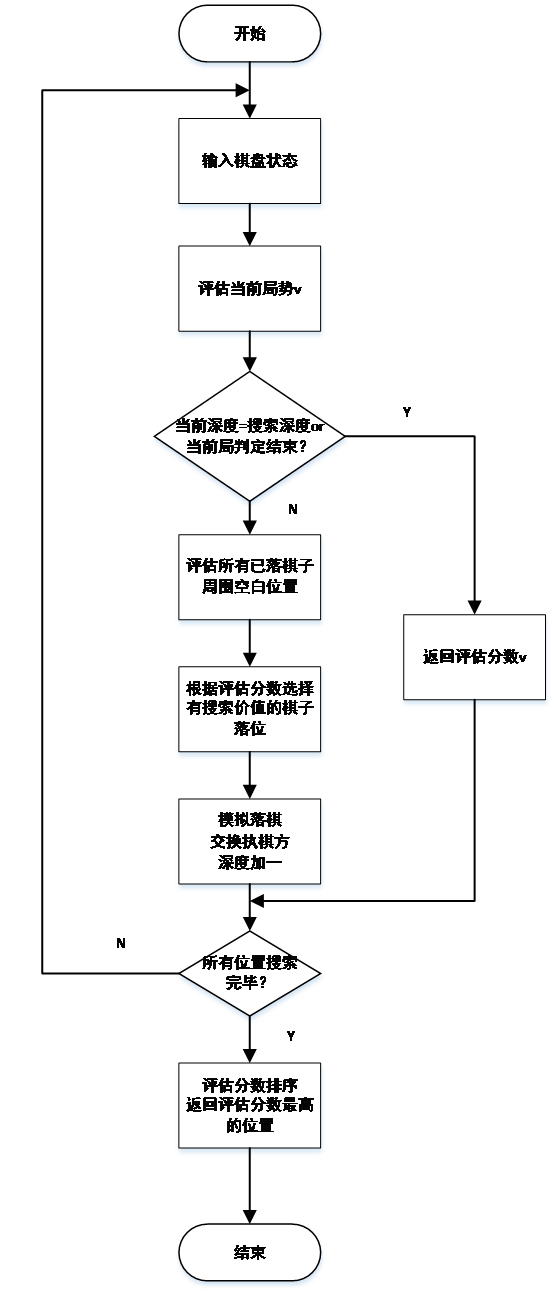
![7Y]F[](5A]J]$039VWB{OH4](http://www.biyelunwen.org/wp-content/uploads/2020/02/lw8380_202021975757155.png)



