增强学习及其应用研究毕业论文
2020-03-20 23:47:10
摘 要
伴随着工业、农业、交通运输业和国防等各个方面快速进一步发展,各个方面都越来越离不开较高的控制性能以及对控制对象高稳定性的要求也就越来越高,因此自动控制学科就有了很大的应用舞台。倒立摆具有结构简单,价格低廉等多个优点,所以从二十世纪五十年代到现在,科学家们对倒立摆的研究进一步加深,是研究控制理论和模型设计的一种实验设备模型,它是具有高阶次、多变量、非线性、强耦合、不稳定特点的系统,倒立摆系统从刚开始的一级慢慢发展到了多级系统,控制手段方法也是更加多种多样。它越来越被用于各个领域的研究。
比如说机器人行走控制技术到如今还没有较好的技术解决方案,它的行走和站立类似于双倒立摆系统(本文研究简单的二级直立倒立摆系统);最贴近生活的,比如在人们生活中广泛应用的时尚的电动平衡车,其原理也是类似倒立摆系统原理;在高科技科研上,比如对火箭、卫星等飞行器的飞行姿态的控制,这些也都是应用到了倒立摆系统;在军事武器研究上,还有由于单级火箭在变弯时容易断裂,由此诞生了多级火箭。这中间所运用到的飞行轨道控制也就是多级倒立摆模型控制了。
本篇论文主要内容在于利用学习的《现代控制理论》知识介绍增强学习的基本内容、研究算法以及二级倒立摆建模、分析和算法仿真等工作,后面将介绍增强学习的几种算法和二级倒立摆模型的建立、研究算法在控制二级倒立摆模型中的应用仿真。最后设计二级倒立摆模型的稳定性控制,并做好数据分析和故障处理,最后还将借助增强学习的学习算法(基于神经网络增强学习),实现直线二级倒立摆模型控制。
关键词:倒立摆;增强学习;现代控制理论;稳定性
Abstract
With the rapid development of industry, agriculture, transportation and national defense and so on, all aspects are becoming more and more inseparable from the higher control performance and the higher stability of control objects. As a result, the subject of automatic control has a very large application stage.Inverted pendulum has many advantages, such as simple structure, low price and so on. So from the 1950s to now, scientists have further deepened their research on inverted pendulum, which is a kind of experimental equipment model for studying control theory and model design. It is a system with the characteristics of high order, multivariable, nonlinear, strong coupling and instability. The inverted pendulum system has slowly developed from the first stage to the multistage system, and the control methods are more varied. It is increasingly used in various fields of research.
For example, the robot walking control technology does not have a better technical solution, its walking and standing is similar to the double inverted pendulum system (this paper studies a simple two-stage vertical inverted pendulum system;Those closest to life, such as the fashionable electric balancing car, which is widely used in people's lives, are similar to the inverted pendulum system;In high-tech scientific research, such as the control of the attitude of rockets, satellites, and other aircraft, these have also been applied to inverted pendulum systems. In military weapon research, there is also the fact that single-stage rockets are prone to break when they bend. This gave birth to a multistage rocket. The orbit control used in this process is called multistage inverted pendulum model control.
The main content of this thesis is to introduce the basic content and research algorithm of reinforcement learning by using the knowledge of "Modern Control Theory", and then introduce several algorithms of reinforcement learning and the establishment of two-stage inverted pendulum model. The application of the algorithm in the control of two-stage inverted pendulum model is studied. Finally, the stability control of the two-stage inverted pendulum model is designed, and the data analysis and fault treatment are done. Finally, the linear two-stage inverted pendulum model control is realized by means of the reinforcement learning algorithm (based on neural network).
Keywords: inverted pendulum; enhanced learning; modern control theory; stability
目录
第1章 绪论 1
1.1引言 1
1.2二级倒立摆研究现状和发展趋势 2
1.2.1国内发展 2
1.2.2 国外发展 2
1.2.3 发展趋势 3
1.3 课题研究意义 3
1.4 课题研究内容 3
1.4.1 增强学习的基本内容、研究现状和发展趋势 3
1.4.2增强学习的几种算法 5
1.4.3二级倒立摆的一般经典控制方法概述 8
第2章 二级直线倒立摆模型建设 9
2.1 二级倒立摆起摆控制研究 9
2.2 二级倒立摆稳定控制研究 9
2.3 二级直线倒立摆系统的硬件组成及工作原理 10
2.4二级直线倒立摆系统数学建模 11
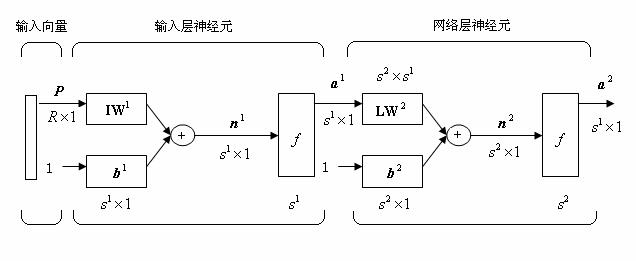
第3章 基于神经网络的二级倒立摆控制 14
3.1 人工神经网络概况 14
3.1.1 神经网络的特点 14
3.1.2 神经网络的应用 15
3.2 人工神经网络的基本理论 16
3.2.1 人工神经元模型 16
3.3 BP算法原理 18
3.4二级直线倒立摆的 BP 神经网络控制 18
3.4.1BP 网络的规划 18
第4章 二级直线倒立摆仿真及结果分析 20
4.1 MATLAB仿真 20
4.2 BP算法数学推导 21
4.3控制效果比较 25
4.4人工神经网络控制待解决的问题 27
结论 28
中外参考文献 29
致谢 31
附录 32
第1章 绪论
1.1引言
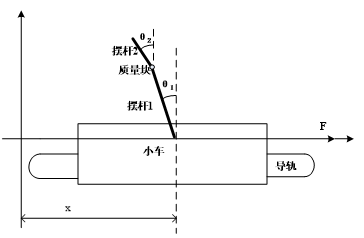
对于倒立摆的研究我们开始从模型的构成谈起,首先它是小车在轨道L上滑动行驶的一个动态稳定过程。让小车和传送带链接在一起,而传送带与力矩电机接在一起成为一个链接动力结构。一共两个摆杆,上下摆杆均要围绕转动中心点q点上下转动。电机是模型的动力系统,主要作用控制让小车、转轮等部分。最终可以让上下摆杆稳定在垂直方向上的平衡点。
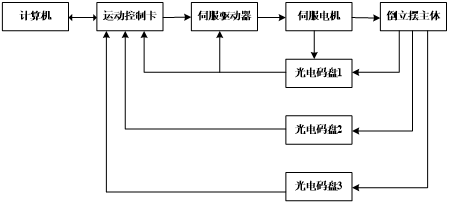
二级倒立摆的结构简图如图1.1的监督管理功能,主要功能是实时画面,数据采集等;数据采集卡安装在计算机内,利用计算机完成模/数、数/模转换;用于电压和功率放大的功率放大器;系统的执行元件-电机;系统的测量元件-电位计,这些元器件和组件完成的工作有以轨道中心点为参考点的小车相对位置数据、以铅垂线为参考的下摆角位移、以下摆延长线方向为参考方向的上摆角位移。采集实验数据,用MATLAB编写相应的算法程序仿真,来比较不同增强学习控制算法下的控制效果。
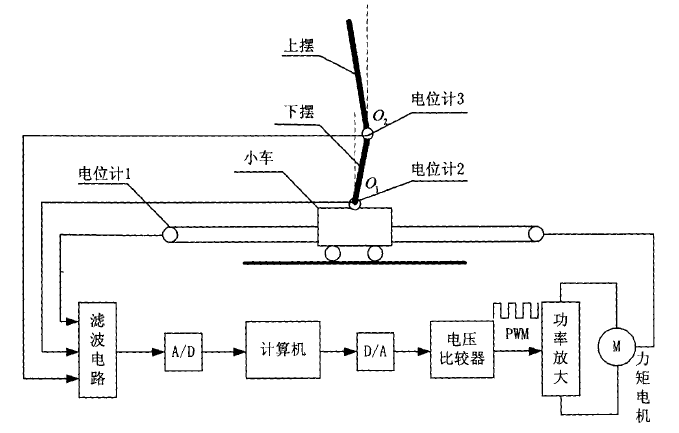
图1.1 二级倒立摆系统的计算机控制系统
1.2二级倒立摆研究现状和发展趋势
围绕着倒立摆系统模型的控制主要的就是其中摆杆起摆和整个系统模型的稳定性控制两大问题。两者相比,目前对于稳定性的研究成果更为显著一些。
1.2.1国内发展
倒立摆系统因其优越的特点,易于实验室的实现。在我国的研究开始于一九六零年,我国的科学家就已经对倒立摆系统开始研究,并进行其稳定性和起摆控制研究。在后来的研究,八十年代时期国内研究倒立摆的集中在高级院校,如中国科技大学成为研究倒立摆系统的主要阵地之一,直至目前,香港固高公司和加拿大Quanser公司生产的研究倒立摆的系统依旧是国内采用研究倒立摆系统的主要对象。
我国科学家领导的一些科研组队倒立摆的研究有了一定的成果。并且在2001年李洪兴科学家等人利用了模糊控制理论对三级倒立摆系统进行研究和学习,实现了对具体实物系统的稳定控制。后来有北京师范大学的数学系科学家李洪兴的一组人员完成了对平面运动三级倒立摆实物系统实现了稳定的控制。我国各大院校和教授对倒立摆科研项目的研究仍在进行中。未来将会实现对多级倒立摆系统实现稳定控制。
1.2.2 国外发展
对于国外对二级倒立摆的研究相对于我国要早,查阅书籍知道美国麻省理工学院最早开始对于倒立摆系统的研究,是在50年代年就开始了。在1966年国外专家Schacfer和Cannon应用Bang-Bang控制理论,将一个曲轴稳定在倒置位置。而后到了二十世纪六十年代末期,以典型不稳定而且非线性研究系统提出的倒立摆系统。从此二级倒立摆模型成为当时世界的研究热点和宠儿。多被用于对非线性、不稳定性、快速性系统的控制能力,在世界范围内引起了巨大的反响。在亚洲的其他国家也在不断地研究倒立摆系统,主要研究阵地也集中在高校范围内,例如日本的东京工业大学;韩国的釜山大学。
1.2.3 发展趋势
研究本课题的同时也要了解一下一级倒立摆的出现和研究发展。一级倒立摆最初是由科学家在研究火箭发射用到的助推器原理而来的。在对一级倒立摆研究理论和成果的基础之上,又继续研发了平面、悬挂等实验模型。倒立摆模型的级数也在从最初的一级,二级进步到多级模型。就目前国内外对于二级直线倒立摆的研究问题主要集中在对小车行驶轨道上摆的自起摆研究以及对上、下摆杆稳定控制问题,另外还有网络远程控制等。将来倒立摆的研究方向将更加趋向于多极向,多参数,更强稳定性发展。
1.3 课题研究意义
研究和学习倒立摆有哪些困难呢?首先,研究倒立摆不能仅仅只局限于单级系统,我们还要研究更多级的,这也就意味着级数的增加带来的控制难度倍增;此外,倒立摆本身是非线性的系统,本身研究就有难点;最后,其理论的理解难,需要更好的实验理论和平台。倒立摆系统本身具有非线性、多变量和强耦合特点,由此吸引着很多科学家的强烈关注。同时这也是对不稳定模型控制的例子,可以作为对不稳定对象控制的典例,对于自动控制领域拥有重要意义。并且由于直线倒立摆系统成本较低,结构简单,有利于在实验室条件下实现对其的建模和仿真。
1.4 课题研究内容
1.4.1 增强学习的基本内容、研究现状和发展趋势
1.4.1.1增强学习的基本内容
增强学习、监督学习和非监督学习是机器学习算法的最常见方法,其中强化学习也就是所说的增强学习。
增强学习就是将情况映射为行为,也就是去最大化收益。学习者并不是被告知哪种行为将要执行,而是通过尝试学习到最大增益的行为并付诸行动。增强学习算法所要完成就是通过多次的数据支持来进行纠错,不断地纠错和反馈就是为了最终获得一个累计回报。对于需要被控制的模型来说,增强学习算法思想的进入可以使系统‘智能化’,自动完成所需要进行的工作和行为动作。RL(reinforcement learning)增强学是从环境状态到动作的映射,一般的话就把这个映射称为策略。接下来我们介绍一下增强学习和监督学习的不同。
增强学习和监督学习的区别:
1. 增强学习是Trail-and-error(试错学习)它是一种自学习纠错过程,通过建设模型的反馈系统与环境和反应的相互对比,最后达到最优解。
2. 由于增强学习要求的原始信息少,所以在获得结果信息之后的反馈结果过程就会延长,即延迟回报问题。与此同时,增强学习还面临着由此带来的后果。在得到指令状态信息之后,获得的正负回报如何及时分配的问题。
增强学习的一个挑战是exploration和exploitation之间的权衡。
Exploration是尝试之前没有执行过的动作以期望获得超乎当前最有行为的收益。
Exploitation是执行根据历史经验学习到的获得最大收益的动作。
1.4.1.2增强学习的研究现状
最近的几年里,增强学习所拥有的成就和技术在很多领域得到了应用,比如机器智能学习,自动控制等。其在各个领域的应用也不断强化着增强学习的理论和算法,尤其是在数学基础研究取得很大进展的基础上。这几年里各大研究领域对于增强学习的研究在一下三个方面:理论、算法和应用。目前,世界范围内对于机器人的研究局限在自适应学习方面,而增强学习理论的发展课题可以弥补其发展的短板,对于优化机器人研究算法有很大的意义和帮助。目前,对于强化学习理论的研究内容分为:收敛性和基础理论两个方面。
1.4.1.3增强学习的发展趋势
近几年,由于DeepMind成功地将强化学习(reinforcement learning)运用在AlphaGo上,机器首次在复杂任务上取得了超过人类的表现,如最近出现的机器算法跟国棋大师的对决中处于劣势地位的新闻,使得强化学习成为目前机器学习研究的前沿方向之一。增强学习最早期的应用仅仅就是局限在智能控制领域,可是现如今我们所见到的增强学习应用的范围不仅仅是局限于此,如近年来非常火爆的汽车自动驾驶,机器人行走等。2013年底DeepMind发表文章Playing Atari with Deep Reinforcement Learning,首次成功地将深度学习运用到强化学习任务上,通过无监督学习实现从纯图像输入来玩Atari 2600游戏的效果。之后DeepMind的算法面临逐步的改进,并且其在智能模拟游戏中达到了一半以上的胜利。后来人们的生活里慢慢出现了无人车等,让我们发现增强学习的理论已经慢慢应用了,并且在默默的改变着我们的生活方式,甚至是世界格局和未来世界的走向。未来增强学习理论和应用研究将会更加丰富多样,朝向智能深度学习方向发展。
1.4.2增强学习的几种算法
1.4.2.1 TD(λ)学习算法
在增强学习理论研究和二级倒立摆模型研究过程中,科学家研究出一种学习算法对强化学习和人工智能领域的研究至关重要,就是时序差分学习。但是依旧是不完美的,没有建设完整体系和理论。Sutton等人通过数学和实验数据来证明了时序差分学习算法在一些条件下的收敛性,提出了对时序差分学习的形式化描述,这一切稳固了对其理论基础的研究。
 算法过程演示如下图1.2和图1.3:
算法过程演示如下图1.2和图1.3:
图1.2 TD(λ)算法
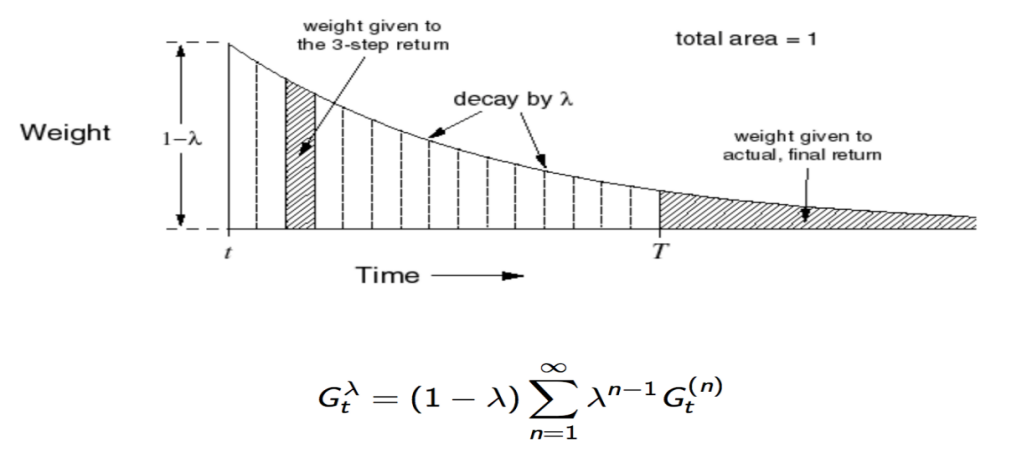 图1.3 TD(λ)算法扩展
图1.3 TD(λ)算法扩展
上面完成了对TD(0)的估计方式,接下来有三步可以拓展到n-step。 1)即TD-target再根据bellman方程展开;2)把TD(i)和TD(j)合在一起求平均;3)下面把能算的TD(i)都算一遍,每一个给个系数,总和为1,这就是TD(λ)。
1.4.2.2 Q-学习算法
表格型Q-学习算法是运用与求解最优函数以及最优值的策略。国外的有关科研工作者很早提出了Q(λ)算法,这一理论中结合了Q-学习算法和TD学习算法中的适合度轨迹(eligibility tracese),这样做的最大的好处就是算法收敛速度大大提升。
 算法过程演示如下图1.4:
算法过程演示如下图1.4:
图1.4 Q-学习算法
这里直接使用最大的Q来更新。SARSA是on-policy而Q-Learning是off-policy是因为SARSA只是对policy进行估计,而Q-Learning的Q则是通往最优。
1.4.2.3 Sarsa学习算法
增强学习的进一步发展就是在线策略(on-policy)学习算法的研发,它也被称为Sarsa算法。在Sarsa算法中,不同于之前的增强学习。因为选择策略和迭代不在一起,他们是各自成为独立单元存在。它是以苛刻学习实现行为函数迭代。
算法过程演示如下图1.5:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: