基于机器学习的动态过程故障诊断方法研究毕业论文
2020-04-12 16:04:05
摘 要
本文先简述了故障诊断的有关背景,并介绍了进行故障诊断的方法分类。紧接着介绍了机器学习的背景及其方法分类,并且指出了两者的联系和研究它们的意义。基于数据的故障诊断方法在现代发展迅猛并且应用广泛,其高效性和易于实现使其具有很大的发展前途。而支持向量机是机器学习中的一种经典算法,利用支持向量机来进行故障检测属于基于数据的故障检测方法中重要的一部分。
本文还介绍了关于经典支持向量机的基本原理并进行了一些数学推导。然后又介绍了由经典支持向量机发展而来的单分类和多分类的支持支持向量机。由于单分类支持向量机很适合故障诊断,故本文后面主要用它作为仿真原理。
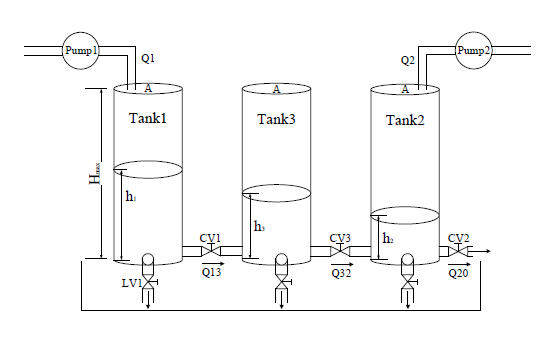
本文主要是利用SIMULINK搭建三水箱模型,得到正常与故障时的数据,再将这些数据作为训练集和测试集,用MATLAB仿真训练单分类支持向量机模型。最后根据仿真结果做了一些总结,指出了支持向量机的一些优缺点。
关键词:故障诊断;支持向量机;三容水箱;MATLAB
Abstract
This article first briefly describes the background of fault diagnosis and introduces the method of fault diagnosis. Then it introduces the background and classification of machine learning, and points out the relationship between them and the significance of studying them. The data-based fault diagnosis method has been rapidly developed and applied widely in modern times. Its high efficiency and easy implementation make it have a promising future. Support vector machine (SVM) is a classical algorithm in machine learning. The use of support vector machines for fault detection is an important part of data-based fault detection methods.
This article also introduced the basic principles of classical support vector machines and performed some mathematical derivation. Then we introduce the single-category and multi-class supportive support vector machines developed by the classical support vector machine. Because single-class support vector machine is suitable for fault diagnosis, it is mainly used as a simulation principle later in this article.
This paper mainly uses SIMULINK to build a three-tank model, obtain normal and fault data, and then these data as a training set and a test set are used in MATLAB to simulate a single-category support vector machine model. Finally, some conclusions are given based on the simulation results, and some advantages and disadvantages of the SVM are pointed out.
Key Words:Fault diagnosis, SVM, matlab, three water tanks
一、绪论
1.1研究背景及意义
随着现代科技技术的迅猛发展,大型设备日趋复杂化,其功能、结构和智能化程度不断提高。然而,设计新的机械设备很重要,维持现有设备的良好运行也很重要。
诸如汽轮机、发电机组、风机、水泵等化工、能源等行业的主要设备一旦出现故障,不仅设备受损,生产停工,造成巨大的经济损失,更严重的是可能危及人身安全,造成环境污染。当今社会的发展对复杂系统的安全运行以及维护保障提出了严峻的挑战。
长期以来,大量研究人员在复杂系统故障诊断与维护方面进行了大量的科学研究。状态监测与故障诊断系统不仅可以判断和识别设备的工作状态,也可以对故障进行早期预报,防患于未然。对机器系统、工程结构和工艺过程的智能故障诊断的研究能降低监测的复杂性,提高诊断能力,所以很有必要。
1.1.1故障诊断的概念及意义
从可接受的,通常的和标准的条件来看,故障是系统至少一个特征属性的所不允许的异常。从故障诊断的角度来看,故障可分为三类:致动器故障,传感器故障和部件故障。
故障诊断,一般指查找设备或系统的故障的过程。用来检测寻找故障的程序称为诊断程序,对其它设备或系统执行诊断的系统称为诊断系统。
系统故障诊断是对系统运行状态做出判断,看是否有异常情况发生,并根据诊断为系统故障恢复提供依据。要对系统进行故障诊断,首先必须对其进行检测,在系统发生故障时,对故障的类型、部位及原因进行诊断,最终给出解决方案,实现故障恢复。
故障诊断的主要任务有:故障检测、故障类型判断、故障定位及故障恢复等。其中:故障检测是指与系统建立连接后,周期性地向下位机发送检测信号,通过接收的响应数据帧,判断系统是否产生故障;故障类型判断就是系统在检测出故障之后,通过分析原因,判断出系统故障的类型;故障定位是在前两部的基础之上,细化故障类型,诊断出系统特定的故障部位和故障原因,为故障恢复做准备。故障恢复是整个故障诊断过程中最后也是最重要的一个环节,需要根据故障原因,采取不同的措施,对系统故障进行恢复。
二十一世纪的到来,使得制造业和加工业面临严峻的挑战,形式为能源成本不断上升,环境法规日益严格以及全球竞争加剧。虽然先进控制被广泛地认为对于应对这些挑战是至关重要的,但其实施受到了更复杂,更大规模的电路配置,全厂整合倾向的影响,并且在某些情况下,缺乏经过培训的人员使得情况更为复杂。在这些过程操作高度自动化的环境中,检测和分类过程测量异常趋势的算法就变得至关重要。
1.1.2故障诊断的方法分类及特点
故障诊断推理方法的研究是故障诊断的核心,其实质是设备状态多值模式识别问题。目前,关于故障诊断的预测推理方法大致分为三大类:基于数学模型、基于经验知识、基于数据驱动。下面对这三类方法分别进行介绍。
类别一,基于数学模型的故障诊断方法。
基于数学模型的方法需要建立过程较精确的定量数学模型,它必须要清楚地知道过程的机理结构。因此,基于模型的方法适用于能建模,传感器多的具有充足信息的系统。其优点是能深入系统本质的动态性质和实现实时诊断。而缺点也很明显:当系统模型未知、不确定或具有非线性时,这种方法不易实现。对于复杂的工业过程来说,准确详细的数学模型往往很难得到,这就限制了基于数学模型的故障诊断方法的应用。基于模型的典型方法有:状态估计法,参数估计法,等价空间法,分析冗余法等。
类别二,基于经验知识的故障诊断方法。
基于经验知识的方法适用于不易进行数学建模的系统。它包括符号有向图、专家系统等方法。该需要很多复杂高深的专业知识以及长期积累的经验。
类别三,基于数据驱动的故障诊断方法。
基于测试或者传感器数据进行预测的方法称为基于数据驱动的故障预测方法,其中最典型的有神经网络、支持向量机、模糊逻辑和贝叶斯等智能方法。这些方法都能根据历史的训练数据来推断其未来的运行状态,并通过自身采集的数据经分析处理后不断更新预测结果,最终完成对设备运行状态趋势的分析预测。
1.1.3机器学习的概念及背景
从广义上讲,机器学习是一种能够赋予机器学习的能力以让它完成直接编程无法完成的功能的方法。但从实践意义上来看,机器学习是一种通过利用数据,训练出模型,然后使用该模型进行预测的一种方法。
基于数据的机器学习在现代智能技术中占有重要地位。机器学习是研究从观测数据(样本)出发来寻找规律,利用这些规律对未来数据或无法观测的数据进行预测。机器学习比较经典常用的方法有:回归算法,神经网络,支持向量机,聚类算法,降维算法,推荐算法等等。
包括神经网络等在内的现有的机器学习方法都有一个共同的重要理论基础——统计学。传统统计学研究的内容是样本数目趋于无穷大时的渐近理论,现有很多机器学习算法也多是基于此假设。但在实际问题中,样本数量往往是有限的,因此一些理论上很优秀的算法在实际表现中可能不尽人意。
与传统统计学相比,统计学习理论(Statistical Learning Theory 或SLT)是一种专门研究小样本情况下机器学习规律的理论,V. Vapnik等人从六、七十年代就开始致力于此方面的研究。到了九十年代中期,随着其理论不断地发展与成熟,也由于神经网络等学习方法在理论上缺乏实质性进展,统计学习理论开始受到越来越广泛的重视。
统计学习理论是建立在一套较坚实的理论基础之上的一种理论方法。它为解决有限样本的学习问题提供了一个统一的框架,能将很多现有方法纳入其中,有望帮助解决许多原来难以解决的问题(比如神经网络结构选择问题、局部极小点问题等)。同时,研究者们在这一理论基础上发展了一种新的通用学习方法——支持向量机(Support Vector Machine 或SVM),它已初步表现出很多优于已有方法的性能。一些学者认为SVM 正在成为继神经网络研究之后新的研究热点,并将有力地推动机器学习理论和技术的进一步发展。
1.2研究发展状况
关于过程故障诊断的文献很多,从光谱一端的第一原理模型到完全基于历史过程数据的数据驱动或统计方法。特别是后者基于历史过程数据,被视为处理复杂系统的最具有成本效益的方法,并且在过去几十年里已经看到了爆炸性增长。数据驱动的故障诊断可追溯到20世纪20年代贝尔实验室的Walter Shewhart发明的控制图表,以提高其电话传输系统的可靠性。在这些统计过程控制图中,感兴趣的变量被绘制为统计上限和下限内的时间序列。随后由戴明推广,到20世纪60年代,这些统计概念(如Shewhart控制图表,累积和图表和指数加权移动平均图表)已完全建立起来。
这些单变量控制图不利用过程变量之间可能存在的相关性。在过程数据的情况下,由于受到质量和能量守恒原则的限制以及在基本上相同的过程变量上可能存在大量不同的传感器读数,所以存在互相关。这些缺点导致多元方法或多变量统计过程控制及相关方法在过去几年中呈指数增长。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
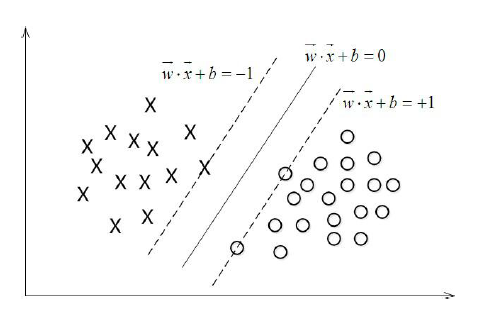
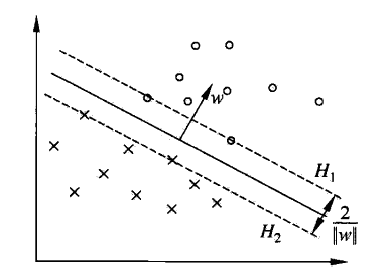
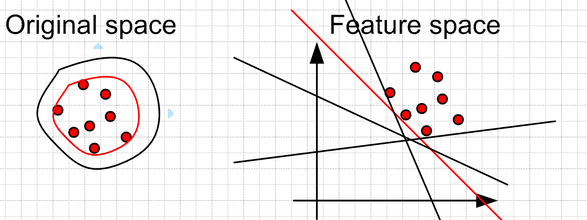
相关图片展示: