基于知识迁移的零样本目标检测方法研究毕业论文
2020-02-19 14:54:58
摘 要
在过去十年中,研究人员在目标检测方面取得了可喜的进展,但这些成果大多依赖于大规模标记训练数据的收集。尽管研究人员一直在努力获取具有更多类别的数据集,但处理过程耗时且繁琐。此外,不可能为罕见的目标收集足够的训练数据。因此,如何在没有训练样本的情况下同时识别和定位这些新的对象实例是一个亟待解决的问题。
本文提出了基于自然语言描述零样本目标检测的方法,旨在通过文本描述同时检测和识别新实例。本文提出了一种新的深度学习框架,将视觉单位、视觉单位注意和词级注意三者结合起来,通过元素乘法实现词的建议亲和性计算。本文描述了使用文本描述构建零样本目标检测框架。该框架对基础对象检测模型的选择具有不可知性,本文的框架基于传统的二阶段目标检测网络Faster RCNN。 本文描述了并实现了基于物体语义对齐的目标检测网络以及基于背景感知方法的零样本目标检测网络。本文对三个具有挑战性的基准数据集进行了实验,大量的实验结果证实了该模型的优越性,实验结果证明该方法的精度超过了已有的方法。
关键词:零样本学习,目标检测,语义嵌入,语义对齐,背景感知的目标检测
Abstract
In the last decade, researchers have made promising progress in object detection. Most of these achievements rely on the collection of large-scale labeled training data. Although re- searchers have struggled to acquire larger datasets with a broader set of categories, the processing procedure is time- consuming and tedious. Furthermore, it is impossible to col- lect enough training data for rare concepts. Therefore, a challenging problem is how to simultaneously recog- nize and locate these novel object instances with no training samples.
Object detection is important in real-world applications. Exist- ing methods mainly focus on object detection with sufficient labelled training data or zero-shot object detection with only concept names. In this paper, we address the challenging prob- lem of zero-shot object detection with natural language de- scription, which aims to simultaneously detect and recognize novel concept instances with textual descriptions. We propose a novel deep learning framework to jointly learn visual units, visual-unit attention and word-level attention, which are com- bined to achieve word-proposal affinity by an element-wise multiplication. To the best of our knowledge, this is the first work on zero-shot object detection with textual descriptions. Since there is no directly related work in the literature, we investigate plausible solutions based on existing zero-shot ob- ject detection for a fair comparison. We conduct extensive experiments on three challenging benchmark datasets. The extensive experimental results confirm the superiority of the proposed model.
Key Words:zero-shot learning, object detection, semantics embedding, semantic alignment, background–aware object detection
目 录
摘 要 I
Abstract II
第1章 绪论 2
1.1 研究背景与意义 2
1.2 国内外研究现状 3
1.3 研究内容与组织结构 6
第2章 基于二阶段检测神经网络的零样本目标检测 7
2.1 模型结构 7
2.2 训练阶段 10
第3章 基于语义对齐损失函数的零样本目标检测 11
3.1 基于语义对齐的零样本目标识别 11
3.2 网络训练及损失函数 12
第4章 背景感知的零样本目标检测 15
4.1 基于RCNN的基线方法 15
4.2 背景感知方法 16
4.3 密集采样嵌入空间 17
第5章 实验验证与方法对比 19
5.1 数据集介绍与评价指标 19
5.2 实验结果分析及方法对比 20
参考文献 24
致谢 26
附录A python代码 基于二阶段检测神经网络的零样本目标检测 27
绪论
研究背景与意义
人类只需文字描述就可以建立一个可视对象的识别模型,但到目前为止,大部分的计算机视觉系统还需要对象的图像作为训练数据。最近,有一些学者利用视觉表示,语义文本嵌入的进展和文本描述在零样本图像识别领域进行了一些工作。零样本图像分类的的设置如下:在训练时,为一些类别提供样本,但在测试过程中,模型期望识别出新的类别实例,并且限制了新类在语义上与训练类相关。大多数关于零样本学习的先前工作都解决了分类问题,使用语义词嵌入或属性作为可见类和不可见类之间的桥梁。
通用零样本学习不同于零样本学习,其测试样本可以属于可见或不可见的类别。因此,通用零样本学习的任务比零样本学习更难完成,这是因为所学分类器对所见类别的固有偏见。本文主要研究目标检测中的广义零样本目标检测问题,并将零样本学习作为通用零样本学习的一个特例来处理。
大多数现有的方法都是在完全监督的条件中解决目标检测的问题。在这种情况下,测试期间发生的所有目标类别都是预先知道的,并且在训练期间,所有操作类别的实例都是可用的。但是,对于许多实际应用程序(例如,在Web视频中自动标记操作),完全监控的问题设置是不现实的,在训练期间,无法获得有关某些操作类别的信息。因此,在这项工作中,本文解决了零样本设置下的目标检测问题。
大多数早期的零样本学习方法都基于属性映射[2,15]。另一方面,最近的一些工作[10,18]通过假设能够访问完整的未标记测试数据,来解决数据域偏移问题。这有助于减少在零样本学习中由于训练和测试中的不相交类别而导致的域移位问题。在视频[11,24]中也探索了类似的行为识别的转导策略,以减少对所见行为类别的偏见。然而,这些方法需要未标记的测试数据来微调参数。此外,由于对已见和未见类别进行了类似的处理,偏差仍然存在。相反,有些学者提出了一个通用零样本学习框架,通过引入一个out-of-distribution(OD)检测器来分离已见和未见操作类的分类步骤。因此,对分类器中可见类的固有学习偏差减小。
在过去的几年里,一些基于卷积神经网络的目标检测方法相继被提出。早期的方法从一个对象候选框生成步骤开始,并将每个对象候选框从一组固定的类别中分类为属于一个类。这些方法在卷积神经网络内部生成目标候选框,或者在图像或特征图中直接包含候选区域。这些方法在包含数十到数百个对象类别的小数据集上取得了显著的性能改进。然而,检测大量对象类的问题还没有得到足够的重视。类别样本的数量遵循长尾分布,这导致了仅少数类别拥有大量数据,而许多类别只包含少量数据甚至零样本。 因为获取数千类对象的边界框标注的成本很高,所以将监督检测扩展到分类级别(数万到数十万个类)是不可行的。最近的一些相关研究工作试图降低对图像标注的需求,例如Redmon[1]提出了一种目标检测方法,该方法可以通过使用可用(图像级)类注释作为对象检测的弱监督来检测数千个对象类。
同时,零样本学习在缺乏标注数据的情况下是有效的。这个问题可以在迁移学习的框架中得到解决。在迁移学习框架中,已知类的视觉模型通过利用已知类和新类之间的语义关系转移到未知类。虽然这样的设置在零样本图像分类中得到广泛的应用,但目标检测仍然需要完全监督的训练方式。与图像分类相比,目标检测旨在预测图像中多个对象的边界框位置。虽然分类可以很大程度上依赖于上下文提示,例如飞机与云共存,但检测需要精确地定位对象,并且可能会因背景关联度而损失精度。此外,目标检测需要学习对外观、遮挡、视点、纵横比等的鲁棒性,以便精确地描绘边界框。与完全监督的目标检测相比,零样本目标检测的主要不同之处在于:虽然在完全监督的情况下,增加了一个背景类,以便更好地区分物体(如汽车、人)和背景(如天空、墙壁、道路),但“背景”的含义对于零样本检测来说并不绝对,因为它可能涉及背景“东西”以及未声明/未看到的物体。所以如何准确地区分背景类别和零样本类别是零样本目标检测的一大挑战。
国内外研究现状
本文从与零样本目标检测相关的四个方面进行国内外研究现状的探讨,即:词嵌入,零样本图像识别,目标检测,和多模态学习。
(1)词嵌入
属性(例如,有翅膀)是指实例或类(例如,鸟)所拥有的内在特征,或指示属性(例如,斑点)或注释(例如,有头像)图像或物体。与典型分类(称为实例的命名)相比,属性描述了类或实例。法哈迪等人。 [17]学习了更丰富的属性,包括零件,形状,材料等。另一种常用的方法(例如,人类行为识别,以及属性和基于对象的建模将属性标签作为潜在变量作为训练数据集的潜在变量,例如,以结构化潜在SVM模型的形式,其目的是最小化预测损失。实例或类别的属性描述可用作语义上有意义的中间表示,弥合低级特征和高级类概念之间的差距。
属性学习方法已成为通过在图像和视频理解任务中传递属性知识来弥合语义差距和解决数据稀疏性的有希望的范例。属性学习的一个关键优势是为多任务学习提供直观的机制[7] 和转移学习[8]。特别地,属性学习通过属性共享(即,零射击和一次射击学习)使得能够通过每个类的少数或零实例进行学习。具体而言,零射击识别的挑战是识别看不见的视觉对象类别,而没有任何未见过的类的训练样本。这需要将来自辅助(看到)类的语义信息(具有示例图像)知识转移到看不见的目标类。
Sharma [9] 将一元/二元属性扩展为复合属性,这使得它们对信息检索非常有用(例如,允许复杂的查询,如“短发,大眼睛和高颧骨的亚洲女性”)和识别(例如,找到一个你忘了名字的演员,或者你在大集合中错放的图像)。
在更广泛的意义上,该属性可以被视为一种特殊类型的“主观视觉属性”[10],其表示估计表示在图像/视频中观察到的视觉特性的连续值的任务。这些属性也是属性的例子,包括图像/视频趣味[11],可记忆[12],美学[13]和人脸年龄估计[14]。 Gygli等人研究了图像的趣味性。这表明三个线索对趣味性的贡献最大:美学,不平凡/新奇和一般偏好;最后一个是指人们通常会找到某些类型的事实
场景比其他场景更有趣,例如,户外 - 自然与室内 - 人造。Liu[15] 评估了来自众源配对比较的视频兴趣度预测的不同特征。 ACM多媒体检索国际会议(ICMR)2017年出版了关于多媒体分析在主观财产理解,检测和检索中的应用的特刊(“多模态理解主观性质”1)。这些主观视觉属性可以用作零射击识别以及其他视觉识别任务的中间表示,例如,人们可以通过描述他们的皮肤肤色是多么苍白和/或他们的脸看起来多么胖而被识别。
(2)零样本图像识别
LatEm [11]通过学习多个线性映射将SJE [9]的双线性兼容性模型扩展为分段线性映射,其中选择为潜在变量。 CMT [12]使用具有两个隐藏层的神经网络来学习从图像特征空间到word2vec 空间的非线性投影。与在固定图像特征之上构建嵌入的其他作品不同,[13]在学习视觉语义嵌入的同时训练深度卷积神经网络。类似地,[14]认为视觉特征空间比语义空间更具辨别力,因此它提出了一种端到端深度嵌入模型,它将语义特征映射到视觉空间。 [15]通过将类语义表示投影到视觉特征空间中并在那些投影表示中执行最近邻居分类器来提出简单模型。通过支持向量回归量学习投影,其具有所见类的视觉样本,即特征空间中的类质心。
(3)目标检测
最近关于物体检测的工作主要使用深度卷积神经网络。 早期方法包含获取每个图像的对象候选框,并使用卷机神经网络对这些对象提议进行分类[12-14]。 最近的方法使用单次通过深度卷积网络而不需要对象区域提议[15-16]。 最近,Redmon[17]引入了一个对象检测器,它可以使用边界框和图像级注释来扩展到9000个对象类别。 这种被称为弱监督学习的设置涉及用较低级别的监督学习,即二进制图像标记,用于制作更高级别的预测,即边界框坐标[18]。
通用对象检测的目的是对任意一幅图像中的现有对象进行定位和分类,并用矩形边界框对其进行标记,以显示存在的机密性。通用对象检测方法的框架主要分为两类(见图3),一类遵循传统的对象检测流程,先生成区域建议,然后将每个建议分类为不同的对象类别。另一种方法将目标检测视为回归或分类问题,采用统一的框架直接实现最终结果(类别和位置)。
为了获得一个完整的图像理解,本文不仅要集中精力对不同的图像进行分类,而且要精确地估计每个图像中包含的对象的概念和位置。此任务称为对象检测[1]、[2],通常由不同的子任务组成,如人脸检测[3]、[4]、行人检测[4]、[5]和骨架检测[6]、[7]。作为计算机视觉的基本问题之一,目标检测能够为图像和视频的语义理解提供有价值的信息,涉及到许多应用,包括图像分类[8]、[9]、人类行为分析[10]、[11]、面部识别[12]、[13]和自主驾驶[14]、[15).同时,在继承神经网络和相关学习系统的基础上,这些领域的进展将发展神经网络算法,并将对作为学习系统的目标检测技术产生重大影响。然而,由于视点、姿势、遮挡和照明条件的变化很大,很难通过附加的目标定位任务来完美地完成目标检测。
研究内容与组织结构
本文结构安排如下:
第1章:绪论。主要介绍论文研究的背景及来源,讨论当前国内外的零样本学习以及零样本目标检测的需求及发展现状。
第2章:基于二阶段检测神经网络的零样本目标检测, 该方法利用文本描述以及短期记忆网络构建了新型的零样本目标检测网络
第3章:基于语义对齐损失函数的零样本目标检测,主要描述了通过类间最大化类内最小化的方法重构的损失函数
第4章:背景感知的零样本目标检测,由于零样本类别容易与背景发生混淆,背景感知方法可以在一定程度上消除背景对零样本类别检测的影响
第5章: 实验结果分析以及现有的方法对比。
基于二阶段检测神经网络的零样本目标检测
目标检测在实际中非常重要的应用价值。现有的方法主要集中在有足够的标记训练数据的目标检测或只有概念名称的零样本目标检测上。本章提出了自然语言描述零样本目标检测的挑战性问题,旨在通过文本描述同时检测和识别新实例。本章提出了一种新的深度学习框架,将视觉单位、视觉单位注意和词级注意三者结合起来,通过元素乘法实现词的建议亲和性。本文对三个具有挑战性的基准数据集进行了广泛的实验。大量的实验结果证实了该模型的优越性。本文描述了使用文本描述构建零样本目标检测框架。该框架对基础对象检测模型的选择具有不可知性。本文的框架基于传统的二阶段目标检测网络Faster RCNN。
模型结构
利用文本描述解决零样本检测问题的挑战是如何有效地建立词建议关系。根据文本描述中的每个单词,网络应该能够确定这个词及其上下文是否适合对象建议。对于文本描述,本文对所有这些词的建议关系进行了研究,对所有关系的信任度进行了加权,并对它们进行了聚合,以达到最终的描述建议亲和力。
本章提出了一个新的深度学习框架,来探索单词建议关系,并确定文本描述和目标建议之间的关联性。本文展示了图1中的整个网络体系结构。该网络包含三个分支:视觉分支、语言分支和边界框后悔分支。可视化分支输出可视化单元激活,每个激活决定对象方案中是否存在某些对象模式。语言分支使用具有长短期记忆单元(LSTM)的循环神经网络。对于描述中的每个单词,它生成单位级别的注意和单词级别的注意,以从视觉分支对视觉单元进行加权。单位级别的关注决定了应该关注哪些单位。本文通过单位级注意和单词级注意对所有单位的激活进行加权,并达到最终的亲和力。
视觉特征编码:对于任意大小的图像,Faster R-RCNN框架使用convnet(例如vgg或resnet)来提取中间卷积激活,这些激活被用作特征图。RPN在这些功能图上运行,并输出一组候选矩形对象建议,每个建议都有一个置信度得分。由于这些高分目标候选提案的大小可能不同,因此框架使用一个ROI池层将它们投影到固定的维度表示。本文将每个候选对象建议的固定维表示形式表示为f。RPN是通用的,因为它根据一个对象度量输出对象建议。因此,一个预先训练的视觉概念的RPN可以直接应用于为看不见的新概念生成对象建议。在本文关于网络体系结构的小节的其余部分中,本文使用这些特性表示来学习对已见和未见概念的有用表示。
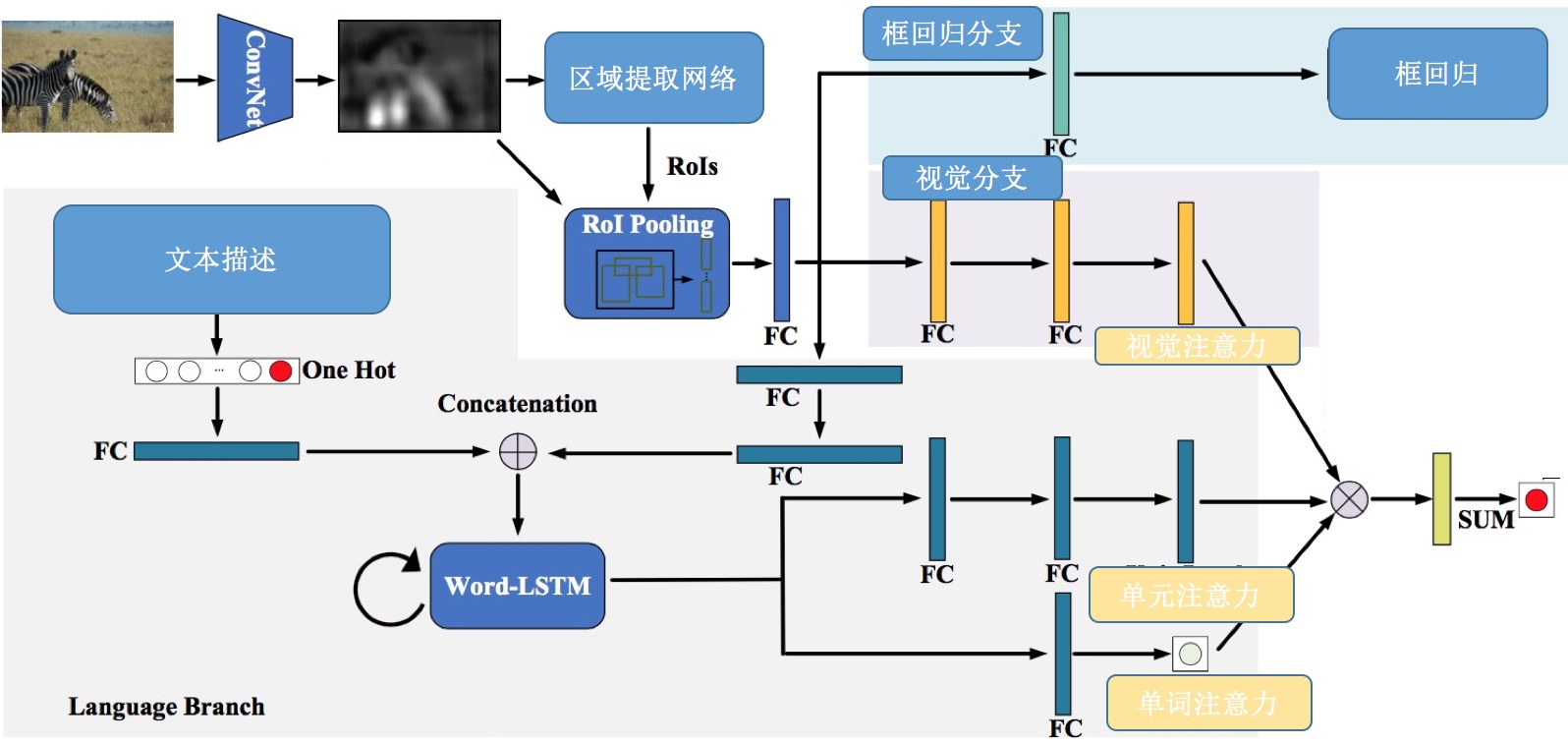
图 2‑1 整体框架
视觉-语义门控注意力机制:本文提出了一种视觉语言门控的注意机制来有效地挖掘词建议关系。直观地说,对于一个给定的词,网络应该为语义相似的视觉部分赋予更大的权重。本文使用了一个LSTM网络训练框架的语言部分,因为它能够捕获顺序数据的时间关系。对于每个语义概念的描述,LSTM网络逐字输出不同视觉单位的注意事项。本文首先将这些单词编码成k维的一个热向量,其中k是词库的大小。给出一个概念的描述,本文使用一个完全连接的层(“w-fc1”)来将t-th字转换为其相应的嵌入特征向量Xtw。此外,本文在每个对象方案的固定尺寸表示之后添加了两个完全连接的层(“V-FC1”和“V-FC2”),从而产生了单词LSTM的视觉特性Xv。然后,在每一步中,本文将XV和XWT的级联作为输入输入LSTM。
LSTM模型包含一个存储单元CT,用于存储前面步骤的历史记录。它有三个控制门,即输入门IT、忘记门FT和输出门OT。LSTM模型使用这些控制门来控制信息的更新和流向。在文献中,LSTM有许多变体,本文使用的LSTM,其迭代方式如下:
| (1) |
| (2) |
| (3) |
| (4) |
| (5) |
代表sigmoid激励函数,表示单位元素的乘法,和是需要进行优化的参数。



