基于深度学习的室内场景目标识别毕业论文
2020-02-19 15:02:00
摘 要
随着计算机的性能得到很大的提升,促进了人工智能研究的发展。深度学习作为人工智能的一个重要方向,它的实际应用极大方便了人们的生活,如自动驾驶、人脸识别、医疗诊断等。众所周知,仓库环境较为复杂,要实现机器的自主导航具有一定的挑战性。
本文主要的研究目的就是利用目标识别技术,结合仓库这个具体场景,为仓库机器人的自主导航提供辅助决策。本文首先分析了仓库的环境,针对货物大小形状不固定的特点,采用整体与部分的方式进行标注。最终定义了人、叉车、AGV、货物、托盘5个目标识别类型。在目标识别模型选择上,由于仓库的人员、货物、设备的流动性大,对目标识别的实时性有较高的要求,本文采用了YOLOv3目标识别模型。在建立仓库图片数据集时,通过Python网络爬虫技术和人工拍摄来获取图片。在建立仓库的YOLOv3目标识别网络模型和仓库图片数据集后,对模型进行训练。最后使用训练的模型对仓库场景中的363张图片进行测试,评估了YOLOv3模型应用于仓库场景的精度。测试结果表明:初次模型测试的mAP值达到了89%以上。通过增加不同环境的数据集图片进行再训练,尽管模型的mAP值下降到78.85%,但增强了模型目标识别的泛化能力。最后采用仓库图片数据集聚类生成的先验框和调整模型的学习率分别来优化模型,使得模型的mAP值提升到86.41%。
关键词:人工智能;深度学习;目标识别;仓库
ABSTRACT
As the performance of computers has been greatly improved, the development of artificial intelligence research has been promoted. As an important direction of artificial intelligence, deep learning greatly facilitates people's lives, such as automatic driving, face recognition, medical diagnosis and so on. As we all know, the warehouse environment is more complicated, and it is challenging to realize the autonomous navigation of the machine.
The main purpose of this paper is to use the target recognition technology, combined with the specific scene of the warehouse, to provide auxiliary decision-making for the autonomous navigation of the warehouse robot. This paper first analyzes the environment of the warehouse, and uses the overall and partial methods to mark the characteristics of the size and shape of the goods. Finally, five target recognition types of people, forklifts, AGVs, goods, and pallets were defined. In the selection of target recognition model, due to the high mobility of personnel, goods and equipment in the warehouse, the real-time performance of target recognition has high requirements. This paper adopts the YOLOV3 target recognition model. When creating a warehouse image dataset, images are captured using Python web crawler technology and manual capture. After the YOLOv3 target recognition network model and the warehouse image data set of the warehouse are established, the model is trained. Finally, 363 pictures in the warehouse scene were tested using the trained model, and the accuracy of the YOLOV3 model applied to the warehouse scene was evaluated. The test results show that the mAP value of the initial model test reached more than 89%. Retraining by increasing the dataset images of different environments, although the model's mAP value dropped to 78.85%, it enhanced the generalization ability of model target recognition. Finally, the a priori frame generated by clustering the image dataset cluster and the learning rate of the adjusted model are used to optimize the model, so that the mAP value of the model is increased to 86.41%.
Keywords: artificial intelligence deep learning target recognition warehouse
目录
第1章 绪论 1
1.1 目的及意义 1
1.2 国内外的研究现状 1
1.2.1 传统的目标识别方法 2
1.2.2 基于深度学习的目标识别方法 2
1.3 研究的基本内容目标及章节安排 4
1.3.1 研究的基本内容 4
1.3.2 研究的目标 4
1.3.3 章节安排 5
第2章 目标识别理论基础 6
2.1 卷积神经网络理论基础 6
2.1.1卷积神经网络概念 6
2.1.2卷积神经网络结构 6
2.1.3 卷积神经网络应用 7
2.2 基于快速检测的YOLO 7
2.2.1 YOLOv1基本原理 7
2.2.2 YOLOv2改进点 9
2.2.3 YOLOv3改进点 9
2.3 本章小结 11
第3章 仓库的图片数据集建立 12
3.1 常用图片数据集的介绍 12
3.2 仓库环境分析 12
3.3 仓库图片的获取 13
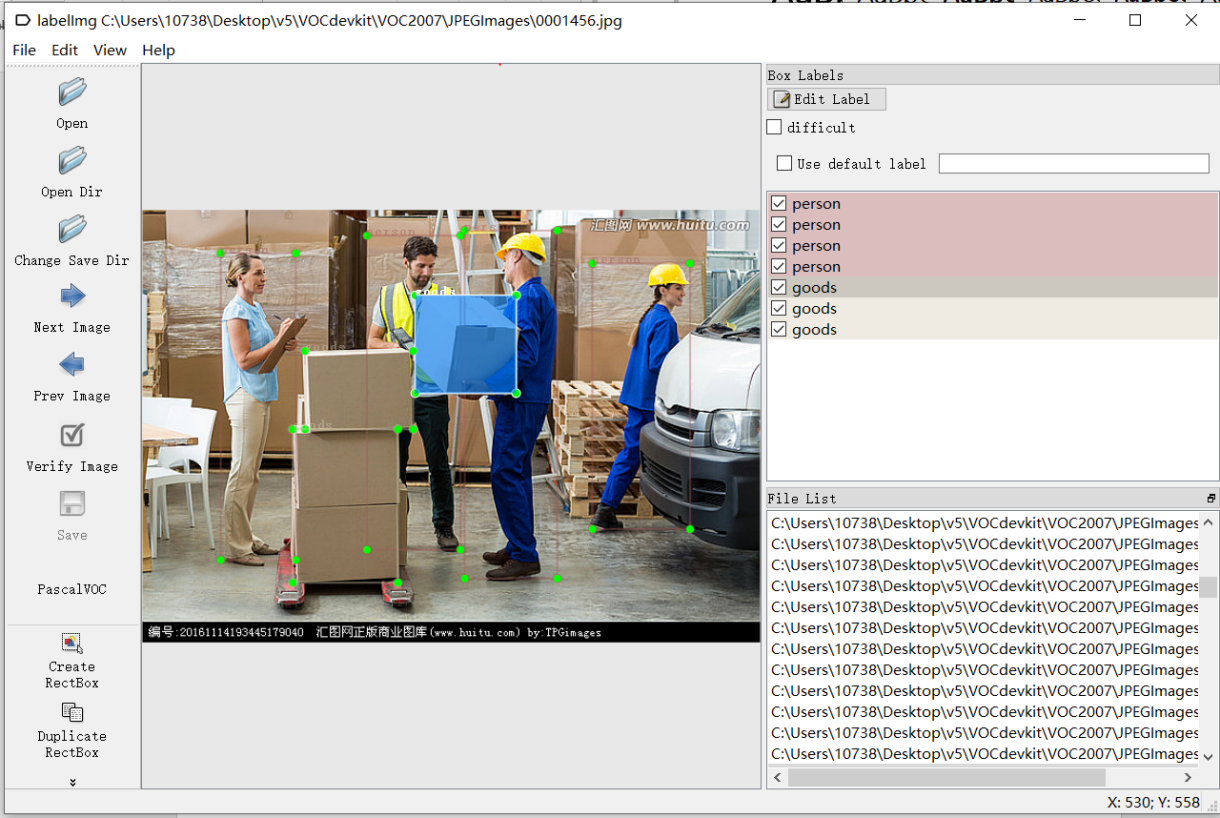
3.4 图片数据标签的制作 15
3.5 本章小结 17
第4章 模型训练与结果分析 18
4.1 数据集训练 18
4.1.1 训练前准备 18
4.1.2 数据集损失值变化 18
4.2 训练结果分析 21
4.2.1 目标识别技术评判指标 21
4.2.2 评判指标结果分析 22
4.2.3 测试图片效果分析 25
4.3 模型的优化 27
4.3.1 扩充数据集图片 27
4.3.2 采用仓库数据集先验框 30
4.3.3 改变学习率 31
4.4 经济效益分析 35
4.5 本章小结 35
第5章 结论 36
5.1 本文的主要工作 36
5.2 下一步工作展望 36
致谢 37
参考文献 38
第1章 绪论
1.1 目的及意义
人工智能研究的迸发,使得人们与机器之间的交互越来越频繁,需求也越来越多。而人类通过与外界交互信息来认识外界环境,最常用的方式就是通过视觉。现代有研究表明,外界传递到人类的全部信息量中,通过视觉接受的信息占比八成以上。同样的,作为计算机,想去了解外界的环境,主要也是通过视觉。图像是一个很重要的视觉信息,它能提供的信息具有形象直观、内容丰富的特点。为了使计算机代替人类去实现图像目标的分类和识别等任务,就要用到图像目标识别技术。
对于人类而言,可以随时随地地通过视觉来实现对外界的任何物体进行准确的识别,但是要想精确识别图像目标对于计算机来说过去一直都是很困难的。近几年来,随着模式识别等新理论的提出和图片处理技术的发展,计算机存储容量与处理器的处理速度提升了许多,使得图像目标识别技术慢慢的可以完成对复杂图像的目标识别和应用到具体的工程中去。科学技术的改进与发展和人类对便捷舒适的生活的追求,让目标识别技术有了更广泛的应用需要。通过目标识别技术,能够将图像或者视频中的物体进行识别并告知系统或者用户该物体所属的类别。同时,还可以实现把目标在图中的具体位置框选出来。
网络全球化、人工智能研究、电子设备的快速发展,导致网络中存在着庞大的图片、语音与视频等信息,同时云计算、GPU的出现,可以轻松获取海量的数据。为了从这些图片或者视频中取得对人类有效的信息,计算机视觉技术在其中发挥的作用显而易见,各科技机构对它的研究越来越多。目标识别技术是指基于计算机图像技术对图像的目标的属性类别进行判断,简单来说就是分类问题,是计算机视觉领域的基础研究,同时也是一个热点问题,具有非常广阔的应用市场[1]。它在人类的实际生活中应用的范围也越来越大,像人脸识别、自动驾驶、医疗诊断、指纹识别、虹膜识别等。
本文致力于通过目标识别技术,为仓库机器人的导航提供帮助和更好的避开障碍物。通过研究目标识别技术,可以提高机器的智能化水平,减少人为的管理成本或者缓解人类的体力劳动,提高工作效率,同时为其企业带来一定的利润。
1.2 国内外的研究现状
室内目标识别的目的就是根据一定的场景正确的辨认出目标。目标识别技术是视觉技术的一个十分重要的研究方向,主要是对其能探测的物体进行识别,如电脑、鼠标、桌子、动物或者玩具等,先通过检测图像内容,检测完后根据物体的特征进行识别,最后进行一定的分析。
近年来,目标识别取得了较大的进步。较为常见的目标识别方法主要分为两大类,传统的目标识别方法与基于深度学习的目标识别方法。
1.2.1 传统的目标识别方法
传统的目标识别方法一般由三步组成,第一步是使用滑动窗口在最初需要检测的图片上生成候选框,主要是为了确定物体的具体位置。因为图片的任何位置都可能存在要识别的目标,同时物体的长宽、大小尺寸同样也不可以确定,故刚开始需要用移动的窗口对整张图片采取一次遍历,还需要定义不同的窗口尺寸。这样方法尽管可以探测到目标所有有概率出现的地方,但是它的不足也是很明显的,需要耗费的时间太多,同时还会出现大量多余窗口,也降低了后面特征提取与目标分类的性能与速度。第二步是通过对第一步生成的图片框进行特征提取,一般的提取特征有如Harr、SURF、HOG等,Harr特征一般用于人的面部识别,HOG特征被用于行人与普通物体的识别。第三步是使用经过训练后的分类器对特征分类,分类完成就意味着得到了目标识别结果,用得比较多的分类器有支持向量机(SVM)模型、AdaBoost、DPM、决策树 (Decision tree)、随机森林(Random forst)等。
传统目标检测主要存在的两个问题:第一个是基于滑动窗口的区域选择方式没有针对性,时间复杂度高,产生大量多余的窗口;二是手工设计的特征对于多样性的变化并没有很好的鲁棒性[2]。
1.2.2 基于深度学习的目标识别方法
对于计算机来说,如果要想完成人的某些工作,需要了解并掌握一定量的知识。基于深度学习的目标识别方法主要是利用深度学习中的卷积神经网络来从大量数据中学习特征。自从Alex Krizhevsky教授实现的深度学习网络AlexNet在ImageNet举办的图片分类竞赛中取得了冠军,深度学习便引起了学术界的兴趣。在以后的ImageNet图像分类比赛中,分类的错误率逐年递减。一直到2015年的时候,应用深度学习模型识别图片分类的错误率开始超过人为标注的,仅为4%,而人工标注的为5%。深度学习在图片识别分类的技术上有了一个新的高度,也带动了目标识别技术的快速发展。研究深度学习目标识别的人也越来越多,代表性的方法主要有R-CNN、SPP、Fast R-CNN、Faster R-CNN、YOLO、SSD等。
(1)R-CNN
2014年,Ross Girshick提出了R-CNN[3]网络模型,通过区域预测和卷积神经网络提取特征的方法对物体识别。该模型在VOC2012图片数据集测试的mAP达到了53.3%。R-CNN通过使用选择搜索算法,配合聚类的方法,把图片分割后进行分组,然后获得不同层次组的框。R-CNN模型主要有4个过程,刚开始对输入的图片生成大量的候选区域;然后通过深度卷积网络对每一个候选区域进行特征提取,再将提取到的特征送进每一类的分类器,判断目标是否是这个类别,最后对目标框选的位置进行一定的修正。该模型的好处就是利用卷积网络增强了对图片特征提取的能力;但是缺点就是卷积网络提取特征的时间长,导致该模型的实性比较差。
(2)SPP
2014年何恺明等提出的SPP-Net算法将空间金字塔的思想加入到R-CNN中,实现了图片的不同尺度输入[4]。SPP中与R-CNN不同的是就是第二个步骤特征提取阶段。SPP是先进行特征提取然后在寻找候选框,与R-CNN刚好相反。但是因为SPP只用对图片的特征进行一次提取,加快了模型的速度。总的来说,SPP相对于R-CNN在速度上有一定的提升。
(3)Fast R-CNN
为了解决R-CNN在存储空间和时间耗费大的问题,Fast R-CNN提出了借助多任务损失函数,把位置修正和目标识别放到一个网络去,并且不再对网络进行分步训练,这减少了用来存储训练过程中产生的特征数据内存,另一方面,采用Rol pooling layer来发挥类似SPP层的作用,使得性能有很大的提升。
(4)Faster R-CNN
Faster R-CNN[5]模型将特征提取、区域预测、目标分类等整合到了一个网络中,相比较之前的模型,Faster R-CNN提高了模型检测速度和识别准确率。
(5)YOLO和SSD
虽然Faster R-CNN在物体识别的准确度上已经很高了,但是在检测的时间上仍然不能达到实时的要求。于是基于回归算法的检测模型被提出了来,这些算法当中只有以YOLO与SDD为主要代表的目标识别方法达到了实时性的要求。
2016年,Redmon等人提出了YOLO网络模型[6]。YOLO把物体识别看作回归问题,直接从卷积网络中预测物体的类别与具体位置,提高目标的检出速度。2016年,Liu等人提出了一种使用单个深层神经网络识别图片中物体的方法SSD[7]。SDD模型吸收了Faster R-CNN中的Anchor机制,为了解决YOLO预测小目标较差的问题使用了不同的尺度。随后在2017年和2018年Redmon等人又分别提出了YOLOv2[8]和YOLOv3[9],再一次将其在目标检测性能方面提升到一个新的高度。
国际上众多机构与学校对目标识别技术展开了广泛的研究,牛津大学、麻省理工等都建立了目标识别的实验室。微软、谷歌、IBM对目标识别的研究也投入了大量的人力物力。
在国内中国科学院的视觉监控研究处于领先地位。国防科技大学的唐聪等人[10]分析了识别场景中经典SSD方法对较小目标识别出现漏检的原因,提出多视窗SSD模型,该方法提增加了目标识别时的AF与mAP的值。在室内场景识别的研究中,上海海事大学的张明等人[11]使用高斯金字塔预处理原图,改进了陈媛媛待测场景图像某点的显著度公式,然后判断该幅图是否有显著度区域,接着利用卷积网络对目标进行特征学习,最后给出分类结果。该方法相比传统的人工特征设计的场景识别算法,具有很好的优势。西南科技大学的吴倩[12]同样也利用了卷积神经网络来实现对室内三维目标的分类识别上。郭济民[13]改进了一个基于密集连接网络的卷积网络,并通过这个网络来提取图片的深度特征,将其应用于SSD检测算法中,在识别速度和准确度上都有较大的提高。熊林[14]提出了利用选择性搜索结合规范化梯度方法来提取图像目标。陈志韬[15]通过改进tiny-yolo 模型和加入NIN卷积层,提高了车辆识别任务中的准确度和位置精度。为了提高高分辨率图片物体识别的识别精度,张亚超[16]提出了基于YOLO的遥感图像视感知目标检测算法。姚晓宇[17]使用检测网络模型和重叠目标检测算法提升了室内目标检测的效果。傅瑞罡[18]对深度学习的HMAX模型(可以实现对特定类的分类)进行了研究改进。衣世东[19]将MobileNet 网络引入到基于VGG16的传统 SSD 算法模型中,提高了模型的识别速度。研究企业当中百度也已经开始进行了汽车自动驾驶的研究。
1.3 研究的基本内容目标及章节安排
1.3.1 研究的基本内容
本文主要是对仓库环境下的目标识别展开研究,利用深度学习的理论知识,选择出一种合理的目标识别的方法,并应用在仓库这个场景中,为机器人提供导航支持。本文的主要研究内容包括:
(1)卷积神经网络的研究。本文对卷积网络和YOLO模型的思想、结构特点展开了一定的研究。
(2)针对在仓库场景中目标识别环境复杂、背景较多的问题,研究了通过YOLO算法可以有效降低背景的误识率,另一方面突出了主要目标的识别。同时使用该算法可以在较高程度上保证目标识别的实时性,减少机器人的移动判断时间,提高工作效率。
(3)针对仓库目标识别的泛化能力和识别精度上,本文通过增加各个不同仓库不同环境下的图片数量,来提高模型物体识别的泛化能力,并通过调整模型的学习率提高了模型的识别精度。
1.3.2 研究的目标
本文通过结合深度学习的相关理论知识,选择出一种合适的目标检测技术,通过建立仓库图片数据集和模型训练并优化,将该目标识别方法应用于仓库内的机器人导航上,为机器人的移动提供技术支持。本文通过研究了YOLO模型的基本原理和网络结构,提出了将YOLOv3模型应用到仓库这个场景中去,对仓库的中重要目标进行识别,获得相关的信息。同时在识别的过程保证一定的目标识别实时性和不低于85%的识别准确率。
1.3.3 章节安排
本文主要以室内目标识别技术研究为主线,以仓库这个具体场景的目标为对象来展开目标识别研究。本文一共分为五章,详细的章节安排如下:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: